
초거대 AI 모델들이 시장에 홍수처럼 쏟아지면서 모델을 개발하는 것 뿐만 아니라 어떻게 사용자에게 "잘", "효율적으로" 제공할 것이냐에 대한 고민이 늘어가고 있습니다. 거대 언어 모델 (Large Language Model, LLM) 이전의 AI 모델의 컴퓨팅 역량은 추론보다는 학습에 집중되었습니다. 학습이 완료된 모델으로 추론을 시도하기 위한 하드웨어 요구사항이 모델을 학습하는 데에 필요한 컴퓨팅 파워보다 월등히 작았기 때문입니다. 모델의 배포자는 실 사용자의 엔드 디바이스 (가령 스마트폰과 같은) 의 NPU 만으로도 추론을 위한 충분한 성능을 확보할 수 있었습니다. 그러나 LLM이 나타나며 상황이 역전되었습니다.
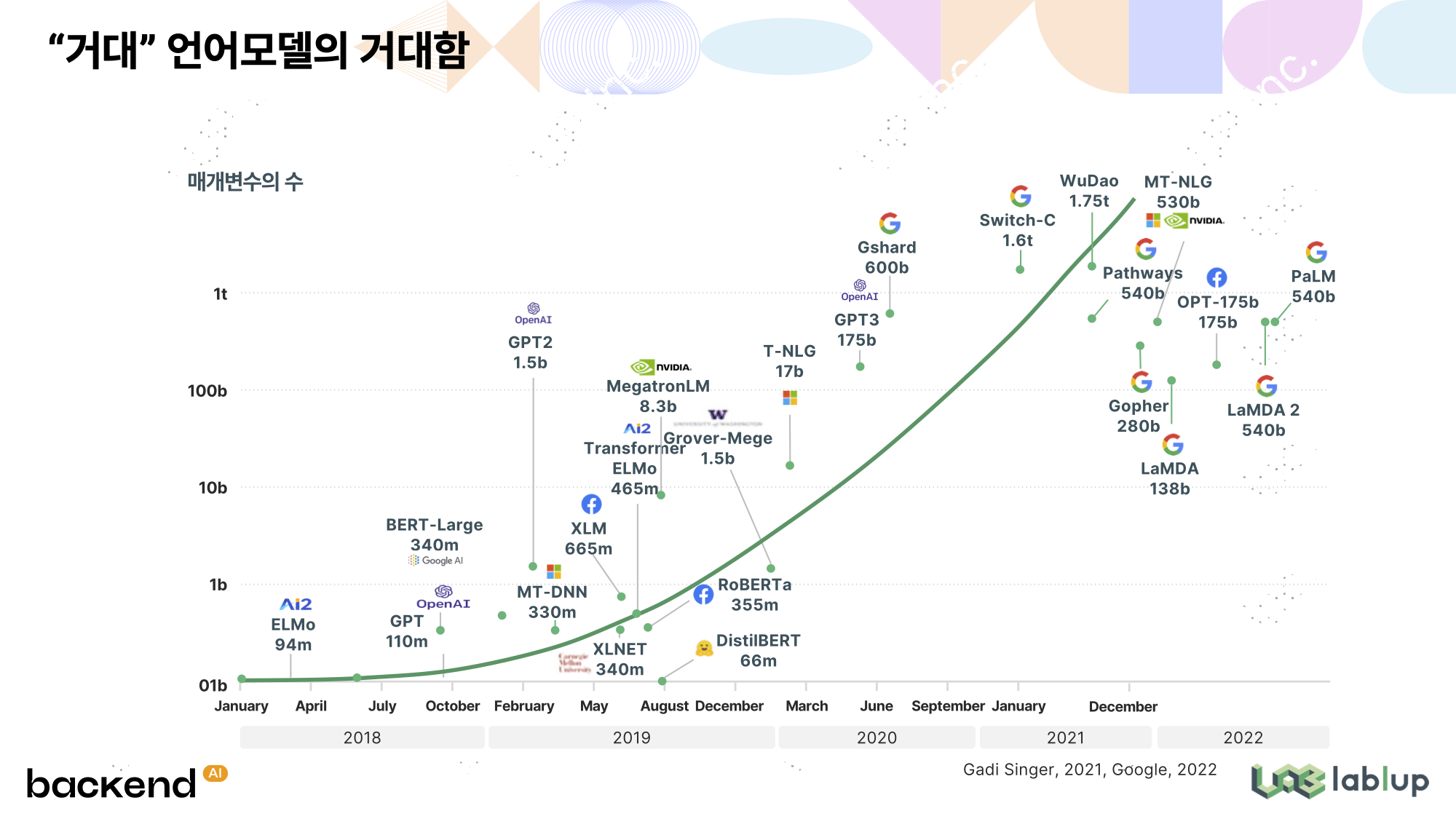
Meta의 OPT 175b 를 예로 들어보겠습니다. OPT-175b는 이름에서 유추할 수 있듯 1750억 개의 파라미터를 보유하고 있으며, 추론 작업을 시행하기 위해 이를 GPU에 적재하는 데에만 대략 320GB 이상의 GPU 메모리를 필요로 합니다. LLM 이전에 유행했던 이미지 처리 계통의 모델들의 최대 요구치였던 4GB에 비하면 엄청나게 큰 차이입니다.
AI 모델의 행태가 이렇게 변화하다 보니, 서비스 자원을 효율적으로 관리하는 것이 안정적으로 서비스를 운영하는 데에 무엇보다도 중요하게 작용하기 시작했습니다. 이번 글에서는 곧 출시될 Backend.AI의 모델 서비스 기능인 Backend.AI Model Service를 미리 살펴보며, Backend.AI를 이용하면 어떻게 AI 모델 훈련부터 서빙까지 하나의 인프라로 효율적으로 운용할 수 있을지에 대해 살펴보겠습니다.
Backend.AI Model Service
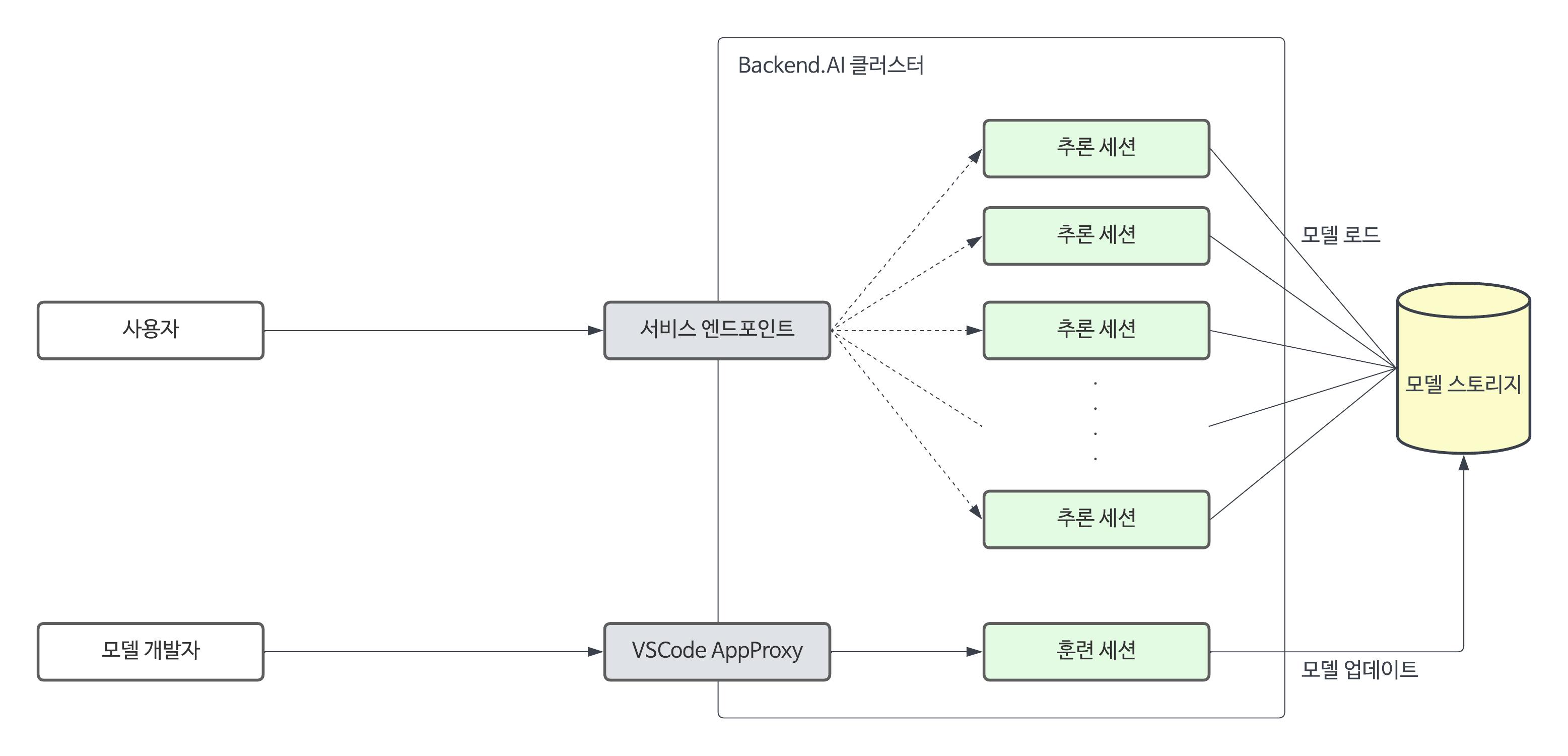
추론 세션
모델 스토리지
Backend.AI를 통해 서비스를 제공할 모델들은 "모델 스토리지" 단위로 관리됩니다. 모델 스토리지는 모델 파일과 모델 서비스를 위한 코드, 그리고 모델 정의 파일로 이루어져 있습니다.
모델 정의 파일
모델 정의 파일은 서비스 제공자의 모델을 Backend.AI Model Service에서 실행하기 위한 정보를 정의하는 공간입니다. 모델 정의 파일에는 모델의 정보, 모델 서비스가 노출하는 포트, 모델 서비스를 실행하기 위해 실행해야 하는 일련의 작업들이 포함됩니다. 모델 서비스에서 자신의 상태를 보고하는 Health Check 기능을 제공할 경우, 해당 정보를 이용하여 불량 상태인 세션의 경우 서비스에서 제외하는 등의 조치가 가능합니다.
models:
- name: "KoAlpaca-5.8B-model"
model_path: "/models/KoAlpaca-5.8B"
service:
pre_start_actions:
- action: run_command
args:
command: ["pip3", "install", "-r", "/models/requirements.txt"]
start_command:
- uvicorn
- --app-dir
- /models
- chatbot-api:app
- --port
- "8000"
- --host
- "0.0.0.0"
port: 8000
health_check:
path: /health
max_retries: 10
다음은 잘 정의된 모델 정의 파일의 예시입니다. 이 예시는 KoAlpaca 5.8B 모델 을 모델 서비스로 실행하기 위한 일련의 과정을 담고 있습니다.
튜토리얼: Backend.AI Model Service를 통해 모델 서비스 해 보기
실제로 Backend.AI를 이용하여 이번 튜토리얼에서는 8bit로 양자화 된 KoAlpaca 5.8B 모델 을 서비스 하는 과정을 따라가 보겠습니다.
API 서버 코드 작성
모델을 제공하기 위한 간단한 API 서버를 작성합니다.
import os
from typing import Any, List
from fastapi import FastAPI, Response
from fastapi.responses import RedirectResponse, StreamingResponse, JSONResponse
from fastapi.staticfiles import StaticFiles
import numpy as np
from pydantic import BaseModel
import torch
from transformers import pipeline, AutoModelForCausalLM
import uvicorn
URL = "localhost:8000"
KOALPACA_MODEL = os.environ["BACKEND_MODEL_PATH"]
torch.set_printoptions(precision=6)
app = FastAPI()
model = AutoModelForCausalLM.from_pretrained(
KOALPACA_MODEL,
device_map="auto",
load_in_8bit=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=KOALPACA_MODEL,
)
class Message(BaseModel):
role: str
content: str
class ChatRequest(BaseModel):
messages: List[Message]
BASE_CONTEXTS = [
Message(role="맥락", content="KoAlpaca(코알파카)는 EleutherAI에서 개발한 Polyglot-ko 라는 한국어 모델을 기반으로, 자연어 처리 연구자 Beomi가 개발한 모델입니다."),
Message(role="맥락", content="ChatKoAlpaca(챗코알파카)는 KoAlpaca를 채팅형으로 만든 것입니다."),
Message(role="명령어", content="친절한 AI 챗봇인 ChatKoAlpaca 로서 답변을 합니다."),
Message(role="명령어", content="인사에는 짧고 간단한 친절한 인사로 답하고, 아래 대화에 간단하고 짧게 답해주세요."),
]
def preprocess_messages(messages: List[Message]) -> List[Message]:
...
def flatten_messages(messages: List[Message]) -> str:
...
def postprocess(answer: List[Any]) -> str:
...
@app.post("/api/chat")
async def chat(req: ChatRequest) -> StreamingResponse:
messages = preprocess_messages(req.messages)
conversation_history = flatten_messages(messages)
ans = pipe(
conversation_history,
do_sample=True,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
return_full_text=False,
eos_token_id=2,
)
msg = postprocess(ans)
async def iterator():
yield msg.strip().encode("utf-8")
return StreamingResponse(iterator())
@app.get("/health")
async def health() -> Response:
return JSONResponse(content={"healthy": True})
@app.exception_handler(404)
async def custom_404_handler(_, __):
return RedirectResponse("/404.html")
app.mount(
"/",
StaticFiles(directory=os.path.join(KOALPACA_MODEL, "..", "chatbot-ui"), html=True),
name="html",
)
모델 정의 파일 작성
API 서버에 맞추어 모델 정의 파일을 작성합니다.
models:
- name: "KoAlpaca-5.8B-model"
model_path: "/models/KoAlpaca-Ployglot-5.8B"
service:
pre_start_actions:
- action: run_command
args:
command: ["pip3", "install", "-r", "/models/requirements.txt"]
start_command:
- uvicorn
- --app-dir
- /models
- chatbot-api:app
- --port
- "8000"
- --host
- "0.0.0.0"
port: 8000
health_check:
path: /health
max_retries: 10
모델 서비스의 세션에서 모델 스토리지는 항상
/models경로 아래에 탑재됩니다.
모델 스토리지 준비
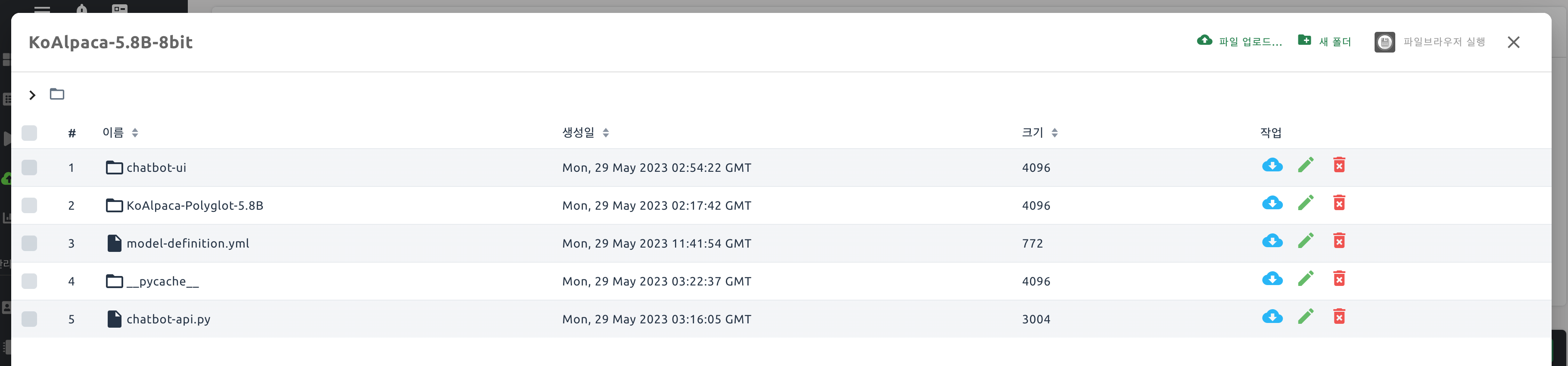
모델 서비스 생성
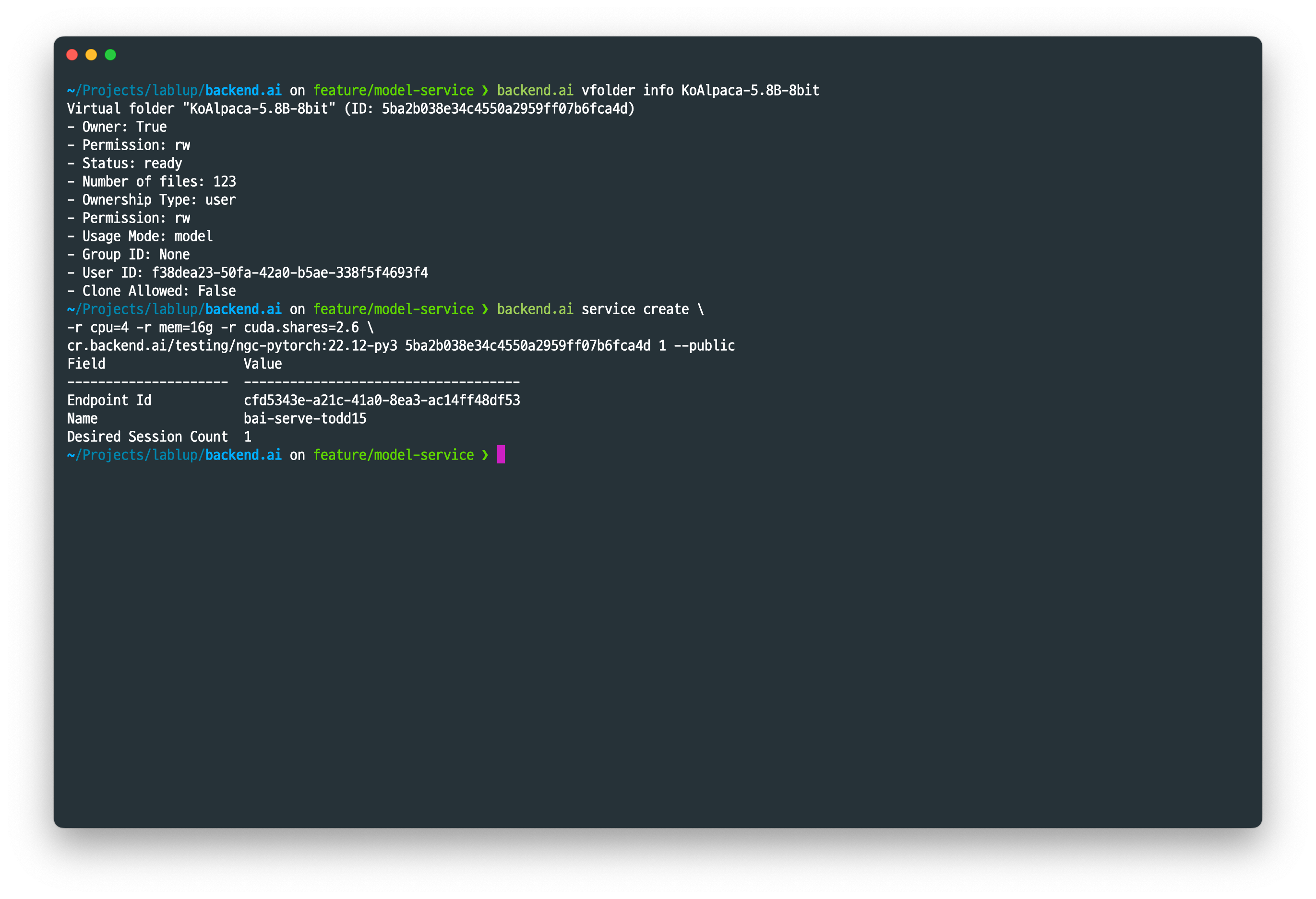
모델 파일과 모델 정의 파일이 모두 준비가 되었다면 이제 Backend.AI Model Service를 시작할 수 있습니다. Model Service는 Backend.AI CLI의 backend.ai service create 명령을 통해 생성이 가능합니다. service create 가 허용하는 인자들은 backend.ai session create 명령과 거의 동일합니다. 사용할 이미지 뒤에는 모델 스토리지의 ID와 초기에 생성할 추론 세션의 갯수를 전달해 줍니다.
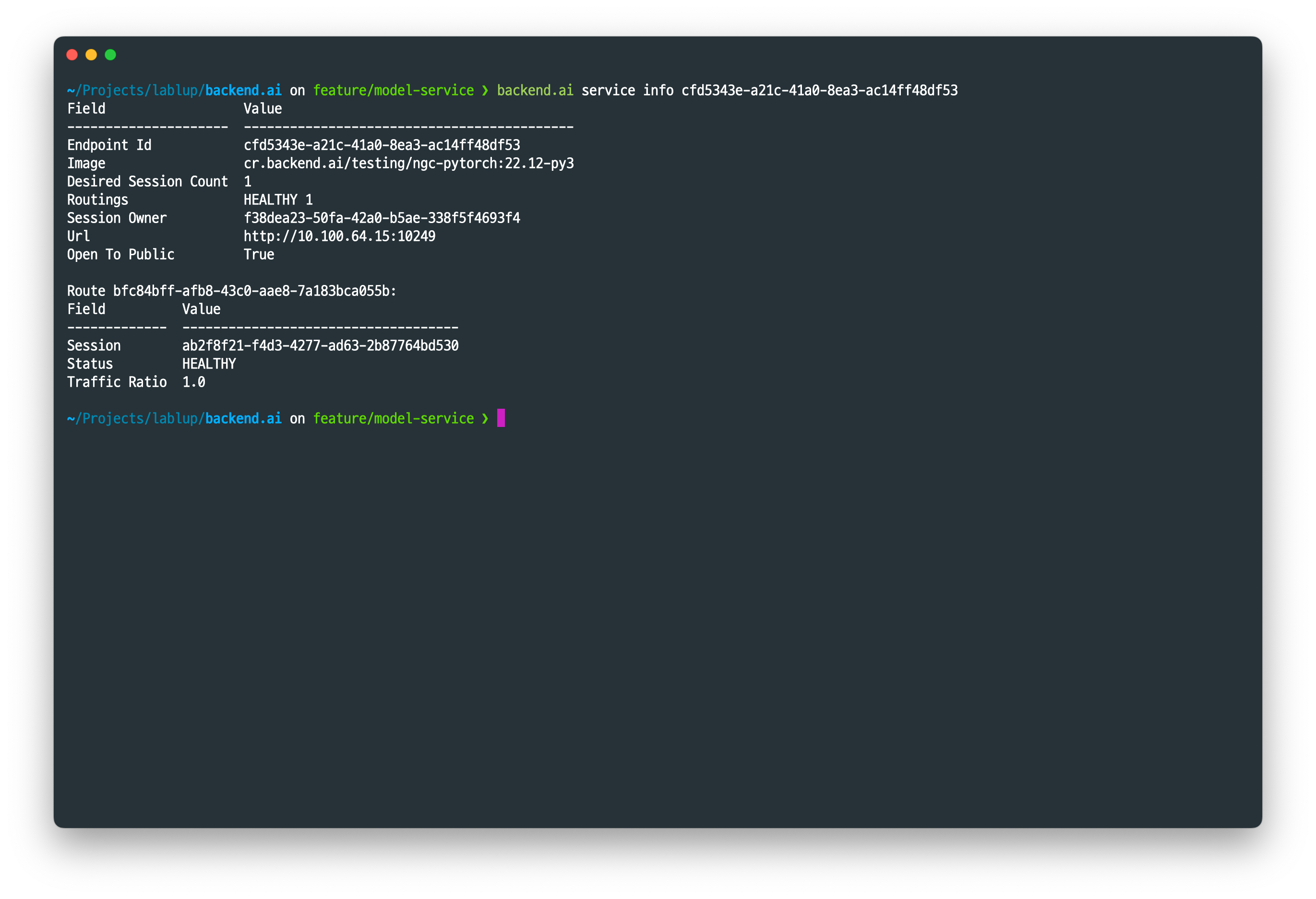
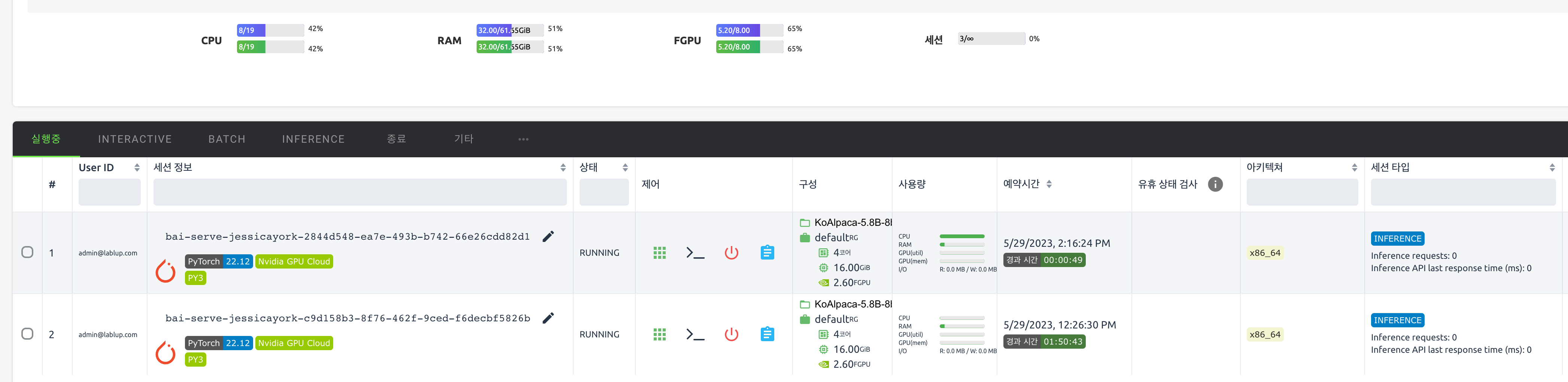
backend.ai service info 를 이용하면 모델 서비스 및 서비스에 속한 추론 세션 상태를 확인할 수 있습니다. 1개의 추론 세션이 잘 생성되었음을 알 수 있습니다.
추론 API 사용
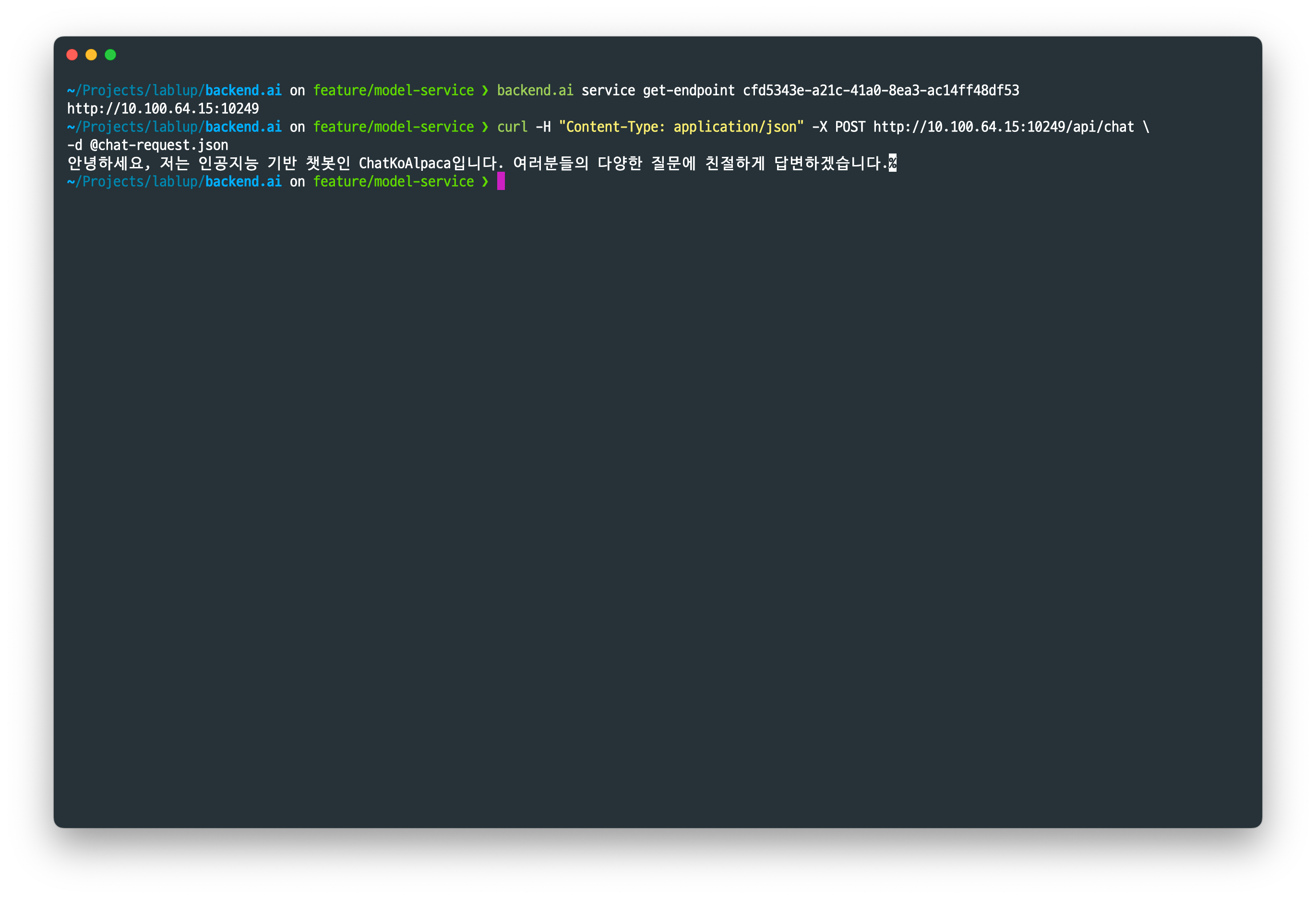
backend.ai service get-endpoint 명령을 이용하면 생성된 모델 서비스의 추론 엔드포인트를 확인할 수 있습니다. 추론 엔드포인트는 하나의 모델 서비스가 생성되고 제거되기 전까지 계속 고유한 값을 가집니다. 하나의 모델 서비스에 여러 개의 추론 세션이 속해 있을 경우 AppProxy는 여러 추론 세션에 요청을 분산합니다.
추론 API 접근 제한
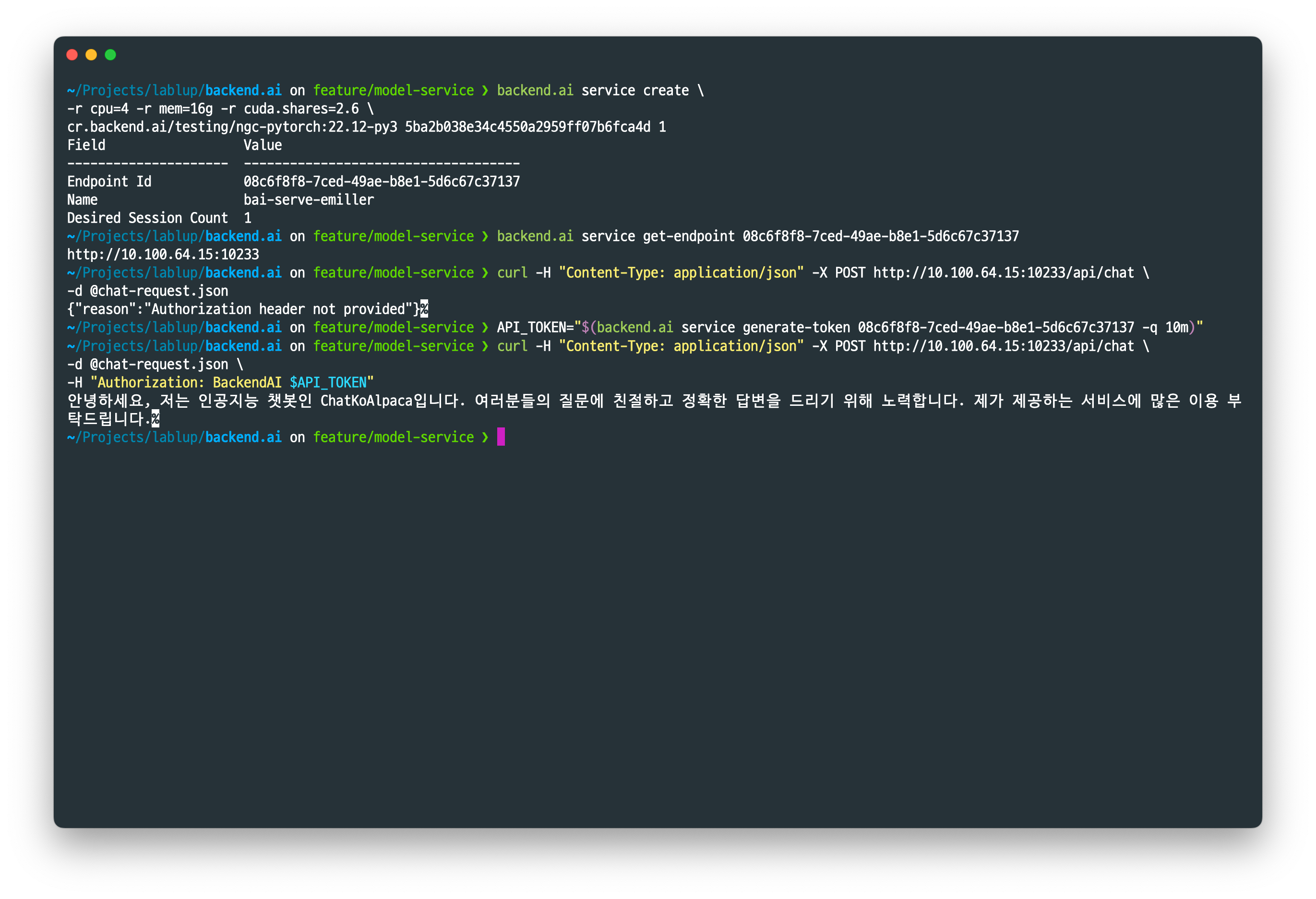
추론 API에 접근 가능한 사용자를 제한하고자 하는 경우, --public 옵션을 제거한 채로 모델 서비스를 시작하면 추론 API에 인증 기능을 활성화할 수 있습니다. 인증 토큰은 backend.ai service generate-token 명령으로 발급할 수 있습니다.
추론 세션 스케일링
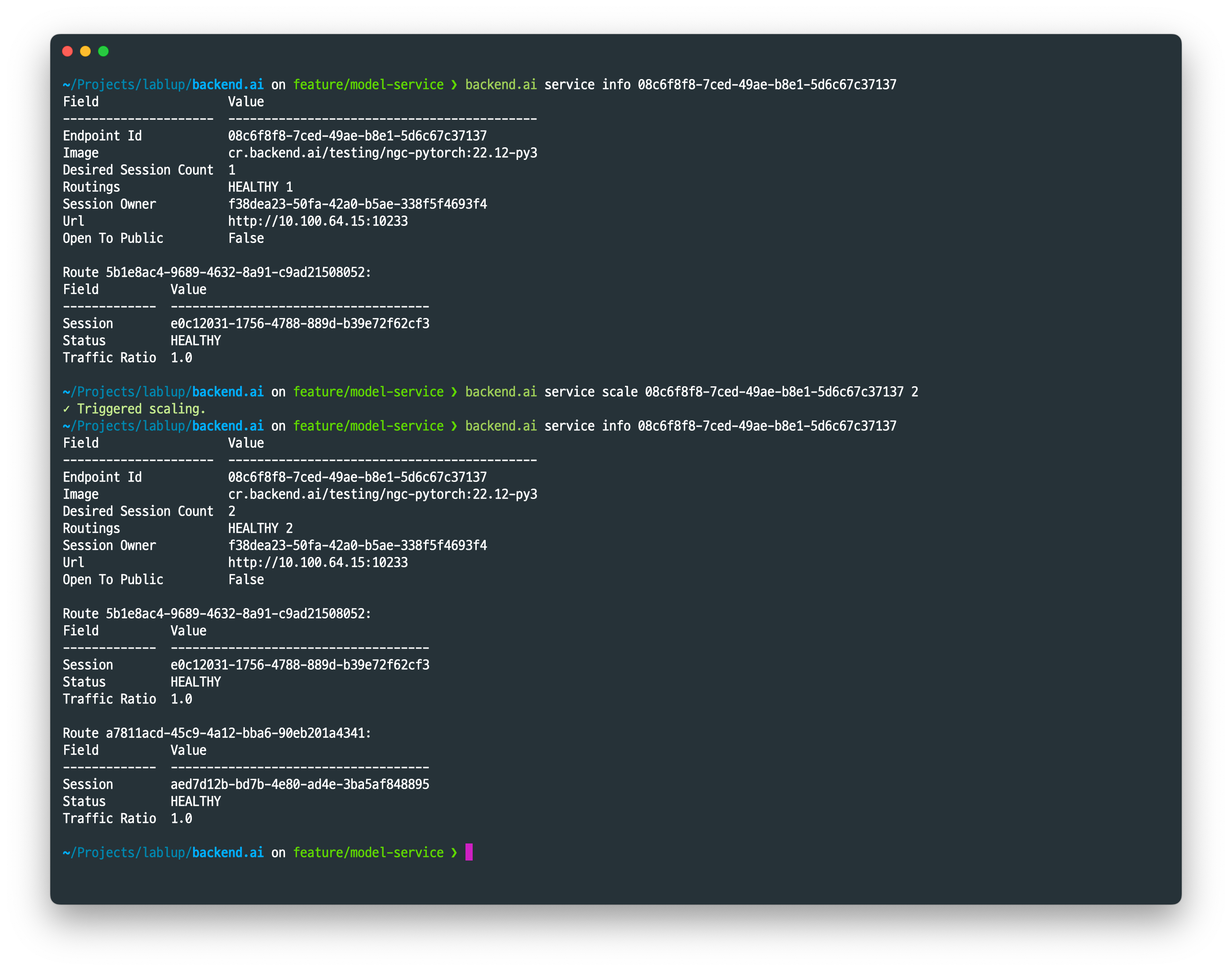
backend.ai service scale 명령을 이용하면 모델 서비스에 속한 추론 세션의 규모를 변경할 수 있습니다.
마치며
지금까지 Backend.AI Model Service와 Model Service 기능을 통해 실제로 모델 서비스를 배포하는 법에 대해 알아보았습니다. Backend.AI Model Service는 Backend.AI 23.03 버전에 정식 배포를 목표로 하고 있습니다. 빠른 시일 내에 Model Service 기능을 정식으로 선보일 수 있도록 노력하고 있으니 많은 기대 부탁드립니다.