
Backend.AI에서는 storage folder 기능을 통해 컨테이너로 이루어진 사용자들의 연산 세션들이 종료되더라도 영구적으로 저장되는 입출력 데이터 및 소스 코드 등을 관리할 수 있도록 하고 있습니다.
이러한 storage folder들은 일반적인 구성에서 클러스터 내부의 스토리지 노드를 NFS로 마운트하는 방식으로 제공됩니다.
이를 통해 사용자의 연산 세션이 어떤 agent 노드에서 실행되든지 상관 없이 항상 각 사용자의 계산 코드는 동일한 storage folder들을 동일한 방식(컨테이너 내에서 /home/work 하위 폴더로 탑재)으로 접근할 수 있습니다.
그러나 이렇게 네트워크를 통해 접근하는 파일시스템을 사용하는 경우, 아무리 스토리지와 네트워크의 속도가 빠르다고 하더라도 수십만~수백만 개의 파일을 읽고 쓰는 것은 여전히 많은 성능 부하를 발생시키며, 최악의 경우 시스템을 다운시키는 현상을 초래하기도 합니다.
단적인 예를 들면, 하나의 폴더에 수백만개의 파일이 들어있는 경우 ls 명령어로 파일 목록을 조회하는 것조차 몇 분 이상이 걸릴 수 있습니다.
이를 완화하기 위해서 래블업에서는 사용자들에게 다음의 2가지 방법을 권장하고 있습니다.:
- 하나의 폴더에 1만개 이상의 파일이 들어갈 것으로 예상되는 경우, 파일 이름을 hashing하여 2단계 이상의 prefix를 적용하여 다단계 디렉토리 구조를 적용합니다.
- 파일 목록 조회 시 보다 효율적인 system call을 사용하여 batching 효과로 성능 오버헤드를 감소시킵니다.
이제부터 각 방법을 살펴봅시다.
파일 이름 hashing하여 다단계 prefix 디렉토리 적용하기
이 방법은 다수의 오브젝트를 파일 형태로 저장하는 많은 소프트웨어가 채택하고 있는 기법입니다.
예를 들면, 어떤 파일의 이름 또는 내용 기반 해시 값이 abcdef12345라면, ab/cd/ef12345라는 경로를 사용하는 것입니다.
실제 주변에서 쉽게 볼 수 있는 사례로, git은 각 커밋의 변경사항들을 나타내는 object 파일들을 다음과 같이 저장합니다:
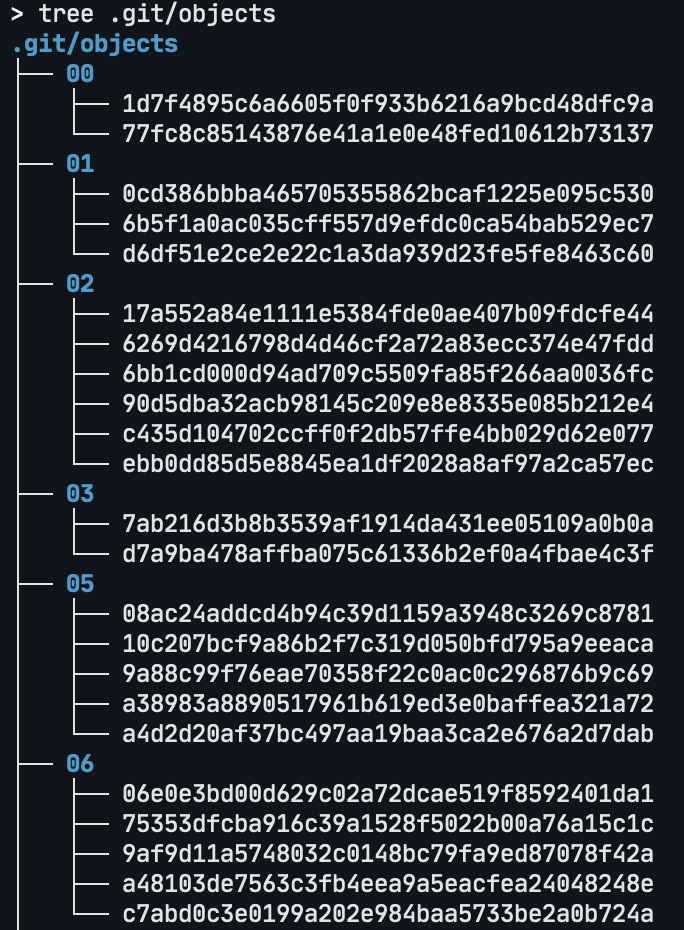
.git 디렉토리에 대한 tree 명령어 실행 예제위의 git 예시에서는 hash의 첫 두 글자만을 활용하여 한 단계의 디렉토리 깊이를 사용하였지만, 보다 많은 파일들을 다루고자 하는 경우 2글자씩 2단계로 묶는 방법들을 사용할 수 있습니다.
16진수의 해시값을 나타내는 문자열에서 2글자 조각은 256가지의 경우의 수를 가지므로, 전체 파일 개수가 1백만 개라고 하였을 때 2단계 깊이를 사용하는 경우 총 디렉토리 수는 256 x 256 = 656536개가 되며 각 디렉토리에는 평균적으로 15개 정도의 파일을 가지고 있게 됩니다. 즉, 최상위 디렉토리 아래에 256개의 디렉토리가 있고, 각 디렉토리에 다시 256개의 디렉토리가 있고, 그 안에 각 15개 내외의 파일이 있는 형태가 됩니다. 이렇게 하면 전체 모든 파일을 목록화하는 것은 여전히 오랜 시간이 걸리지만 다음과 같은 장점이 생깁니다.
- 각 디렉토리 단위로는 훨씬 빠른 시간 안에 목록화가 가능합니다.
- 새로운 파일의 추가·삭제가 빈번하게 발생하더라도 파일시스템 상에서 개별 디렉토리에는 적은 횟수의 수정이 발생하기 때문에 다른 파일들을 읽고 쓰는 데 상대적으로 동기화 부하가 적어집니다.
대신 주의할 점으로는 어떤 해시 함수를 사용하느냐에 따라 분포의 균등함이 달라질 수 있다는 점과, 파일 추가나 삭제 시 단계별 디렉토리를 생성하거나 비어있는 디렉토리를 삭제하는 등의 로직 처리를 주의해서 작성해야 한다는 점이 있습니다.
getdents() system call을 활용하여 파일 목록 조회 batching 적용하기
다음 방법은 파일 목록 가져오는 작업 자체를 더 빠르게 하는 것입니다.
사용자들이 머신러닝 코드 작성을 위해 많이 사용하는 Python 언어의 os.walk() 및 os.scandir() 함수를 비롯하여, UNIX 표준 명령어인 ls는 내부적으로 readdir()이라는 libc 함수를 사용합니다.
readdir()을 사용하는 프로그램은 먼저 opendir() 함수로 대상 디렉토리에 대한 일종의 "디렉토리 스캔" 세션을 얻고 그것을 기반으로 파일 정보를 1개씩 반복 조회한 후 closedir() 함수로 현재 세션을 종료해야 합니다.
파일 개수가 적을 때는 괜찮지만, 파일 개수가 늘어날수록 이 방식은 1개의 파일 정보를 가져오기 위해 매번 라이브러리 및 시스템콜 호출을 수행해야 한다는 점에서 점점 오버헤드가 커지는 문제가 있습니다.

이를 보완하기 위해 나온 것이 getdents() 시스템콜입니다.
역사적으로 위의 readdir() 계열 libc 함수들은 각각에 해당하는 시스템콜을 감싸는 것으로 만들어졌으나 현재의 리눅스 커널에서는 모두 getdents() 계열 시스템콜을 사용하고 있습니다.
getdents()는 디렉토리를 일반 파일처럼 open() 시스템콜을 통해 열고 read() 대신 getdents() 시스템콜을 이용하여 그 파일의 내용을 읽어들이는 방식으로 동작하는데, 이때 1회의 호출마다 사용할 버퍼 크기를 임의로 지정할 수 있습니다.
실제 읽어들여지는 항목의 개수는 파일명의 길이 분포에 따라 매번 차이가 조금 있을 수 있지만, 수백~수천 개의 파일 정보를 한번에 가져올 수 있다는 장점이 있습니다.
여기서 문제는, 호환성을 위해 지원하고 있는 기존의 readdir() 인터페이스는 버퍼 크기를 호출하는 쪽에서 지정할 수 없다는 점입니다.
따라서 라이브러리가 임의의 버퍼 크기를 사용해야 하는데, glibc의 POSIX 호환 구현을 보면 대략 32 KiB 정도를 기본 크기로 사용하고 있습니다.
구체적인 크기는 glibc 버전에 따라 다를 수 있으나, 수십 KiB 정도의 스케일이라고 생각하면 되겠습니다.1
따라서 기존의 readdir() 인터페이스를 통하지 않고 버퍼 크기를 지정할 수 있는 직접 getdents()의 장점을 누릴 수 있도록 프로그램을 작성해야 합니다.
Python에서는 python-getdents 패키지를 이용하면 다음과 같이 복잡한 코딩 없이 getdents()를 쉽게 활용할 수 있습니다.
import os
from pathlib import Path
import sys
import getdents
ROOT = Path("/path-to/target/directory")
def do_scandir():
items = [item for item in os.scandir(ROOT)]
for item in items:
print(item.name)
def do_getdents():
bufsz = 10 * (2**20) # 10 MiB
items = [item for item in getdents.getdents(ROOT, bufsz)]
for _, _, name in items:
print(name)
시험삼아 AWS EC2에서 t3.large 인스턴스를 생성하고 같은 region 내의 EFS 파티션을 마운트하여 1백만개의 1바이트짜리 파일을 만들어 목록 읽기 성능을 비교해본 결과, 최초 접근 시에는 둘 다 1분 정도로 총 지연시간을 비슷하게 소모하였지만, I/O가 아닌 사용자 프로세스 및 커널에서 소비한 시간은 getdents() 쪽이 약 1/3로 줄어들었고, 디렉토리 내용이 시스템의 버퍼 캐시에 들어간 후에는 총 지연시간이 평균 4배 이상 차이(scandir은 3.1초, getdents는 0.7초)가 나는 것을 확인할 수 있었습니다.
즉, 네트워크를 통해 정보를 가져오는 것 자체를 줄여주지는 못하지만, 어느 정도 반복된 읽기·쓰기 및 파일 목록 조회가 발생하는 상황에서는 glibc의 기본 동작보다 좀더 공격적인 batching을 통한 성능 향상 효과를 기대해볼 만하다 하겠습니다.
정리
이렇게 네트워크 파일시스템을 사용할 때 많은 개수의 파일로 인한 성능 오버헤드를 줄일 수 있는 사용자측 기법 2가지에 대해 살펴보았습니다. 아무리 빠른 스토리지와 네트워크를 사용하더라도 이러한 기법들을 적절히 혼합하여 사용하시면, 시스템 안정성을 높이고 불필요한 파일시스템 동기화 오버헤드를 감소시킬 수 있습니다. 이 글이 Backend.AI를 사용하시는 분들뿐만 아니라 대용량 데이터 분석 작업을 하시는 분들에게도 도움이 되었으면 합니다.
래블업에서는 이러한 엔지니어링을 함께 할 인재를 모시고 있습니다. 👉 지원하기
- musl libc 1.22의 경우 2 KiB 정도를, GNU libc 2.31의 경우 32 KiB 가량을 기본으로 사용합니다.↩