
이제는 클래식이 되어버린 AlexNet부터 오늘날 뜨거운 관심을 받고 있는 여러 거대 언어 모델(이하 LLM)들까지, 우리는 필요에 맞게 다양한 모델을 학습하고 평가합니다. 그러나 현실적으로 모델을 여러 번 실행해 보고 경험이 쌓이기 전까지 우리는 학습이 언제 종료될지 가늠하기 어렵습니다.
Backend.AI의 뛰어난 스케줄링은 GPU의 유휴 시간을 최소화하고 우리가 잠든 사이에도 모델 학습이 실행될 수 있도록 하였습니다. 그렇다면 더 나아가서, 우리가 잠든 사이에 학습이 완료된 모델의 결과를 전달받을 수 있다면 어떨까요? 이번 글에서는 FastTrack의 신기능과 Slack을 활용하여 모델 학습 결과를 메시지로 수신하는 방법을 다뤄보도록 하겠습니다.
이 글은 Backend.AI FastTrack 24.03.3 버전을 기준으로 작성되었습니다.
들어가기에 앞서
본문은 Slack App 및 Bot을 생성하는 방법을 다루지 않습니다. 자세한 내용은 공식 문서를 참고하는 것을 권장합니다.
파이프라인 생성하기
모델 학습에 사용할 파이프라인(Pipeline)을 만들어 보도록 하겠습니다. 파이프라인은 FastTrack에서 사용하는 작업 단위입니다. 각 파이프라인은 최소 실행 단위인 태스크(Task)의 묶음으로 표현될 수 있습니다. 하나의 파이프라인에 포함되는 여러 개의 태스크는 서로 의존 관계를 가질 수 있으며, 이 의존성에 따라 순차적으로 실행됨이 보장됩니다. 각 태스크마다 자원 할당량을 설정할 수 있어 전체 자원을 유연하게 관리할 수 있습니다.
파이프라인에 실행 명령이 전달되면 해당 시점의 상태를 그대로 복제하여 실행되는데, 이러한 단위를 파이프라인 잡(Pipeline Job)이라고 합니다. 하나의 파이프라인에서 여러 개의 파이프라인 잡이 실행될 수 있으며, 하나의 파이프라인 잡은 하나의 파이프라인으로부터 생성됩니다.
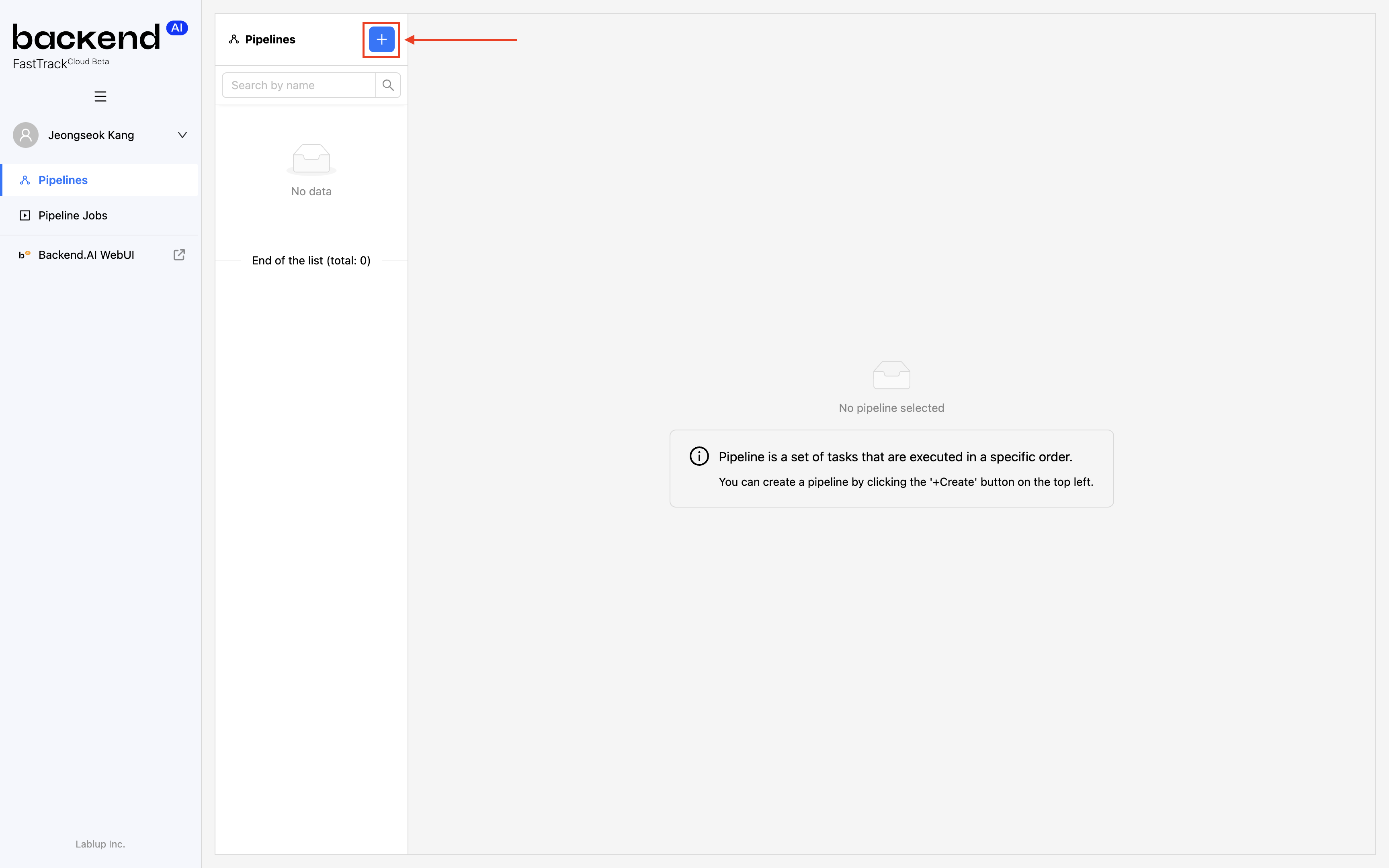
파이프라인 목록 상단에 위치한 파이프라인 생성 버튼("+")을 클릭합니다.
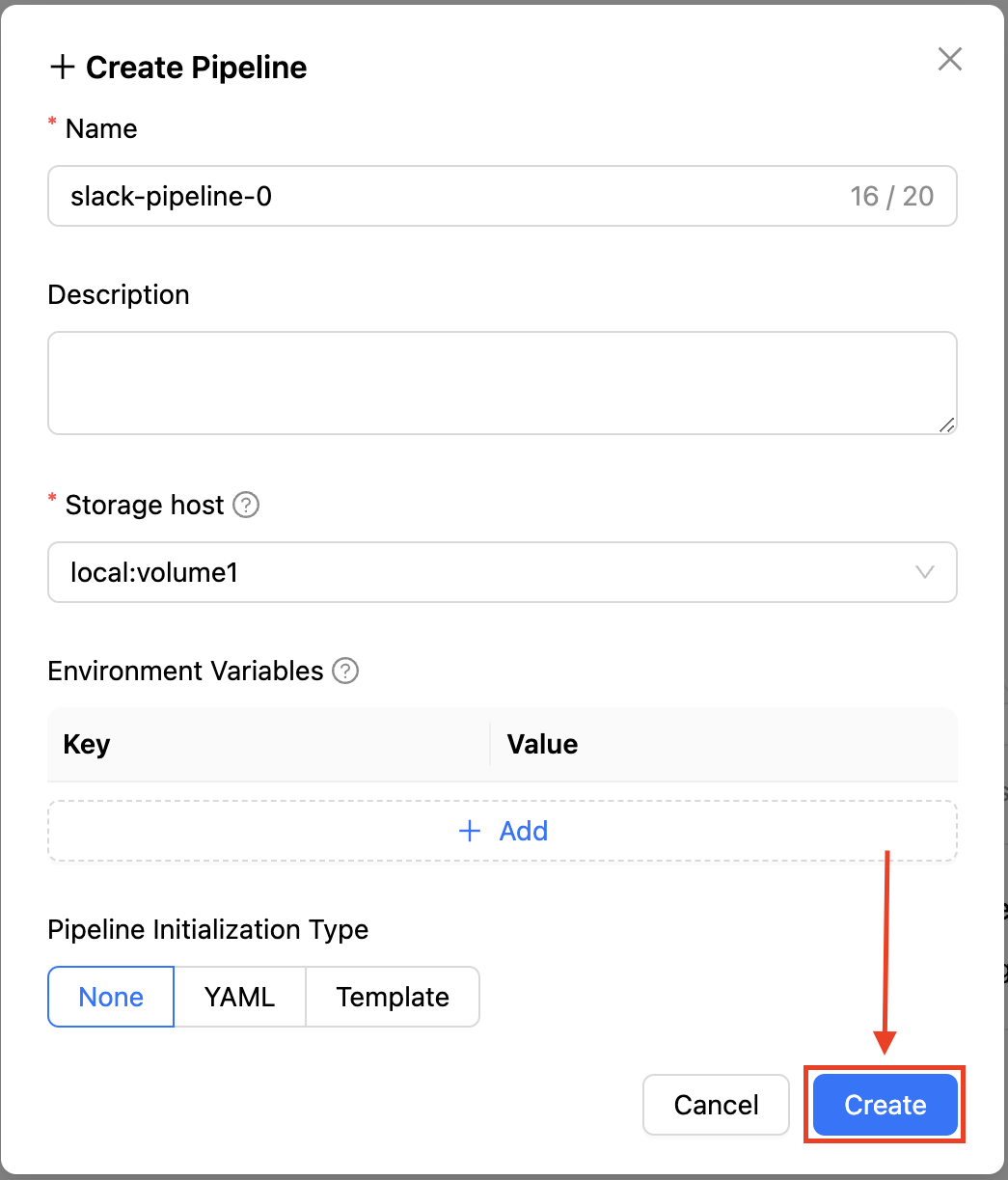
파이프라인의 이름과 설명, 사용할 데이터 저장소의 위치, 그리고 파이프라인에서 공통적으로 적용할 환경변수와 파이프라인 초기화 방법 등을 선택할 수 있습니다. slack-pipeline-0이라는 이름을 입력한 후 하단의 "Create" 버튼을 클릭하여 파이프라인을 생성합니다.
태스크 생성하기
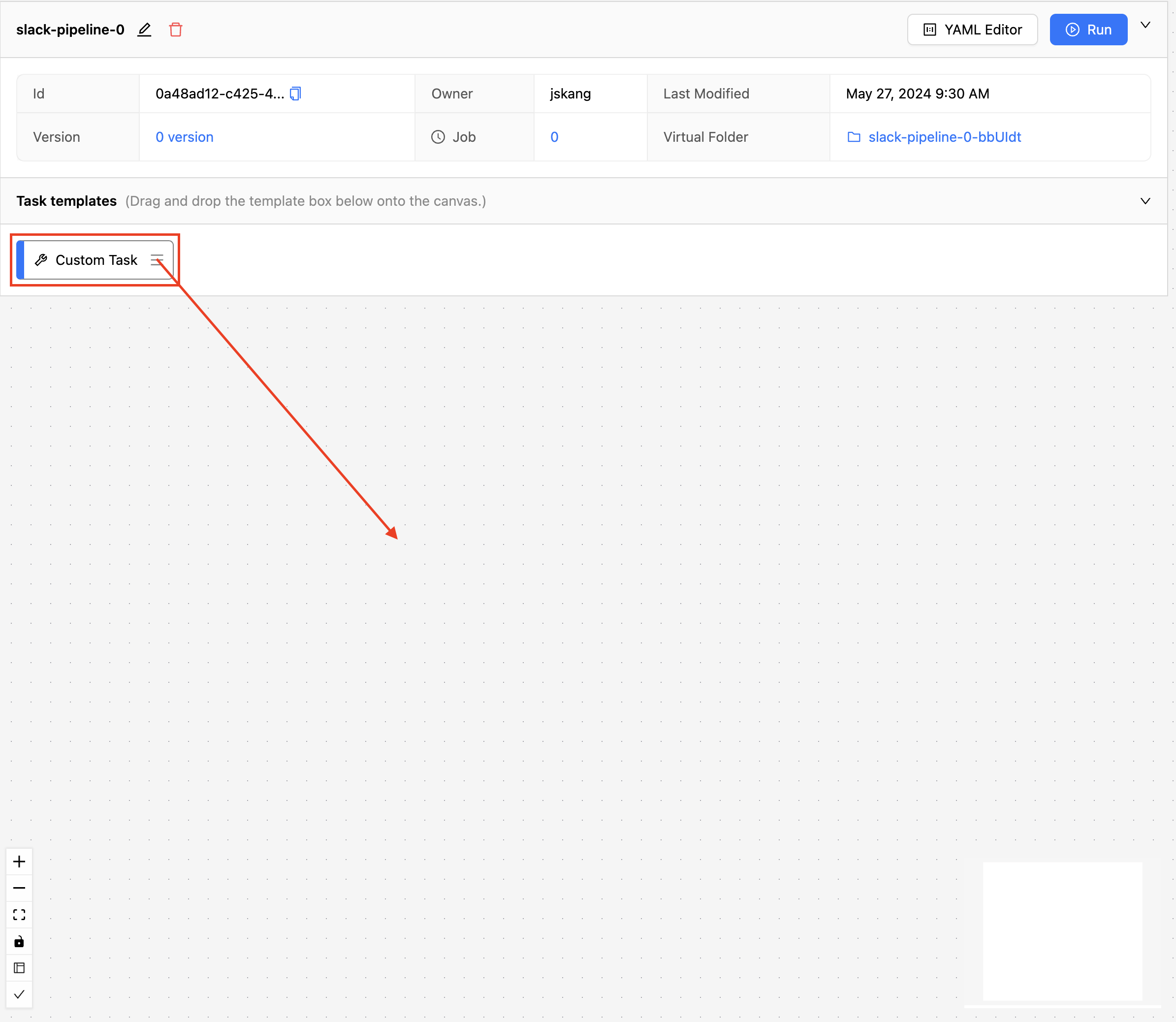
새 파이프라인이 생성된 것을 볼 수 있습니다. 이제 태스크를 추가해 보도록 하겠습니다. 상단의 태스크 템플릿 목록(Task templates)에 있는 "Custom Task" 블럭을 마우스로 끌어와서 하단 작업 공간에 놓습니다.
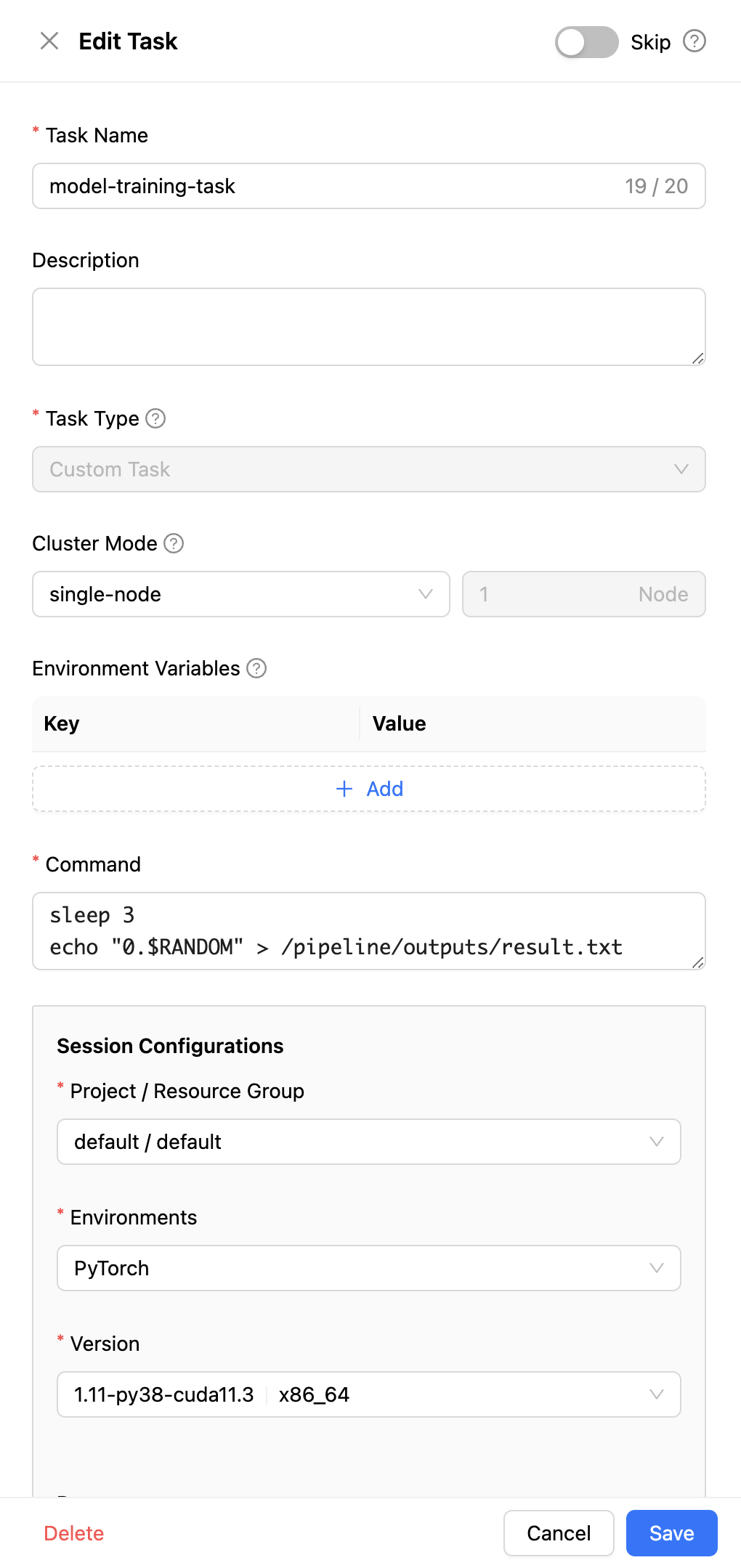
우측에 태스크의 세부사항을 입력할 수 있는 작업창이 나타납니다. model-training-task라는 이름을 주어 태스크의 역할을 나타낼 수 있으며, 모델 학습을 진행하기 위하여 pytorch:1.11-py38-cuda11.3 이미지를 사용하도록 설정합니다. 실제 모델 학습은 오랜 시간을 소요하므로 이번 예시에서는 아래와 같이 간단한 명령을 수행하도록 합니다.
# 3초 동안 동작을 중지시킴으로써 실행 시간이 증가합니다.
sleep 3
# 파이프라인 전용 폴더에 `result.txt` 파일을 생성합니다. 학습이 완료된 모델의 정확도라고 가정합니다.
echo "0.$RANDOM" > /pipeline/outputs/result.txt
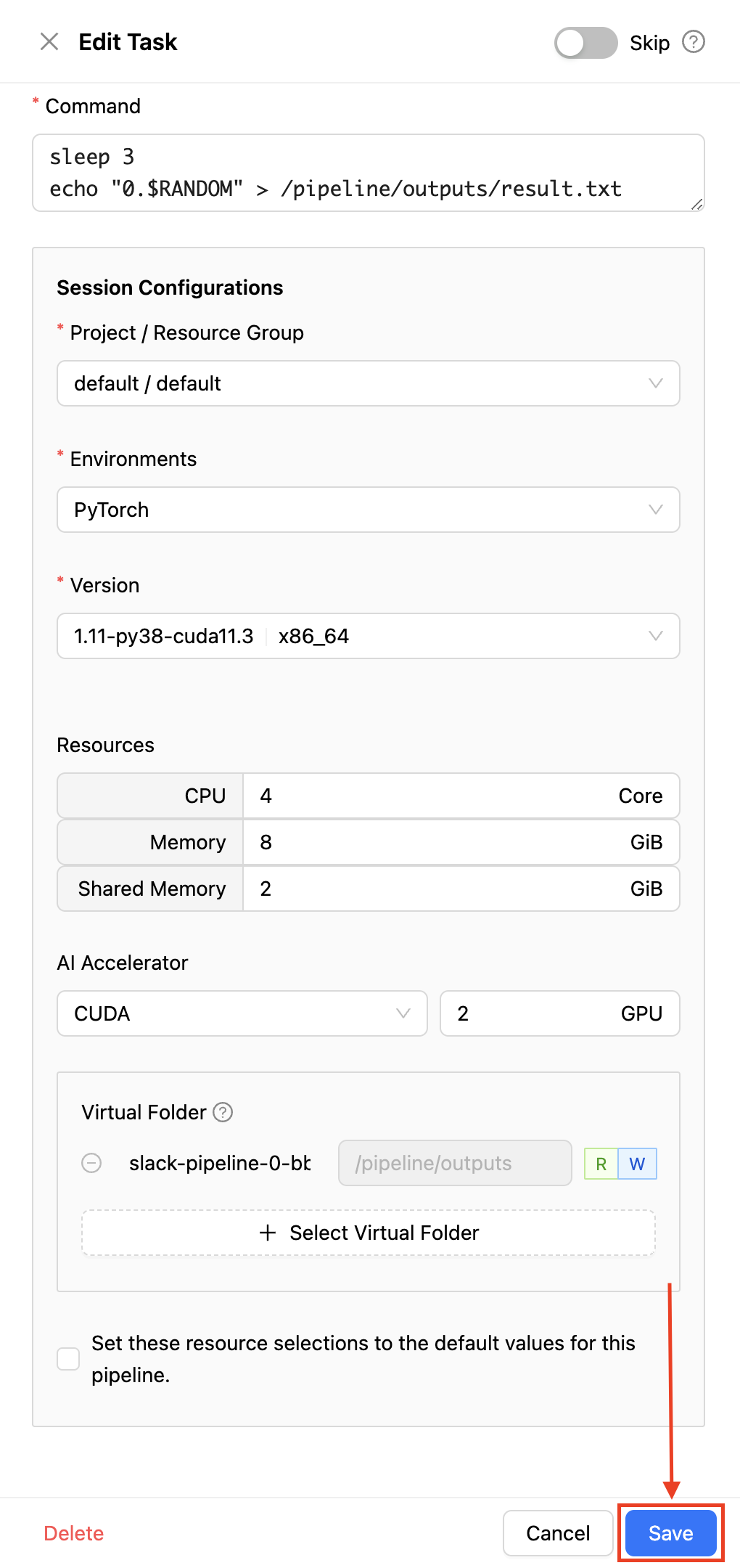
마지막으로 태스크에 할당할 자원량을 입력한 후 하단의 "Save" 버튼을 클릭하여 태스크를 생성합니다.
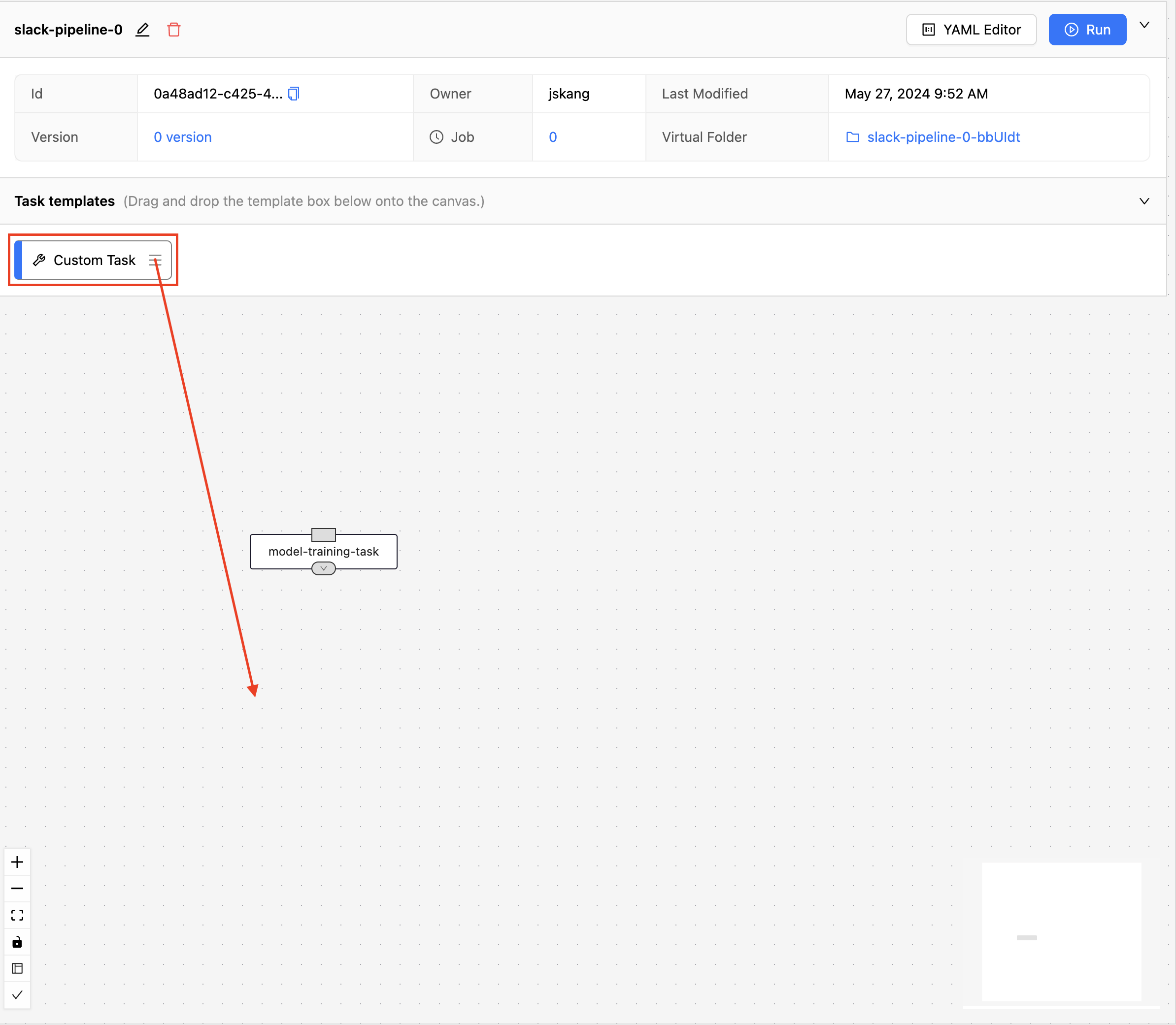
모델 학습 태스크가 작업 공간에 생성된 것을 확인할 수 있습니다. 이번에는 앞에서 저장한 result.txt 파일로부터 수치를 읽어와 Slack으로 알림을 보내는 태스크를 만들기 위하여 다시 "Custom Task" 블럭을 하단 작업 공간에 가져옵니다.
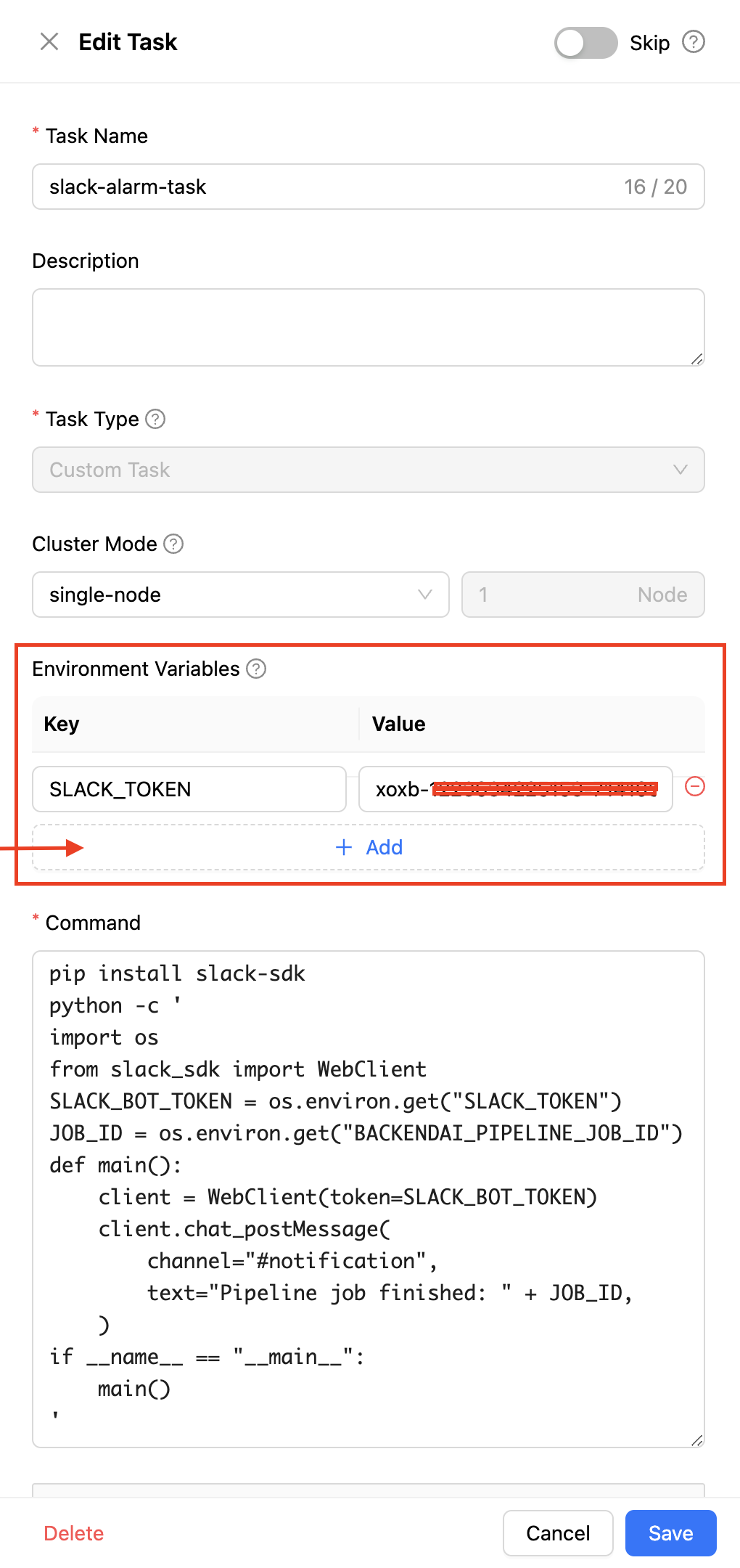
이번 태스크는 slack-alarm-task라고 이름을 설정하고, 아래와 같은 스크립트를 입력하여 Slack에 알림을 보내는 동작을 수행하도록 합니다.
pip install slack-sdk
python -c '
import os
from pathlib import Path
from slack_sdk import WebClient
SLACK_BOT_TOKEN = os.environ.get("SLACK_TOKEN")
JOB_ID = os.environ.get("BACKENDAI_PIPELINE_JOB_ID")
def main():
result = Path("/pipeline/input1/result.txt").read_text()
client = WebClient(token=SLACK_BOT_TOKEN)
client.chat_postMessage(
channel="#notification",
text="Pipeline job({}) finished with accuracy {}".format(JOB_ID, result),
)
if __name__ == "__main__":
main()
'
위 코드는 SLACK_TOKEN, BACKENDAI_PIPELINE_JOB_ID라는 이름의 두 환경변수를 활용하고 있습니다. BACKENDAI_* 형태의 환경변수는 Backend.AI 및 FastTrack 시스템에서 자동으로 추가하는 값들로, 그중 BACKENDAI_PIPELINE_JOB_ID는 각 태스크가 실행되고 있는 파이프라인 잡의 고유 식별자를 나타냅니다.
또 하나의 환경변수인 SLACK_TOKEN는 태스크 단위 환경 변수로 추가된 값으로, 이 기능을 활용하면 코드 변경 없이 다양한 값을 관리 및 변경할 수 있습니다.
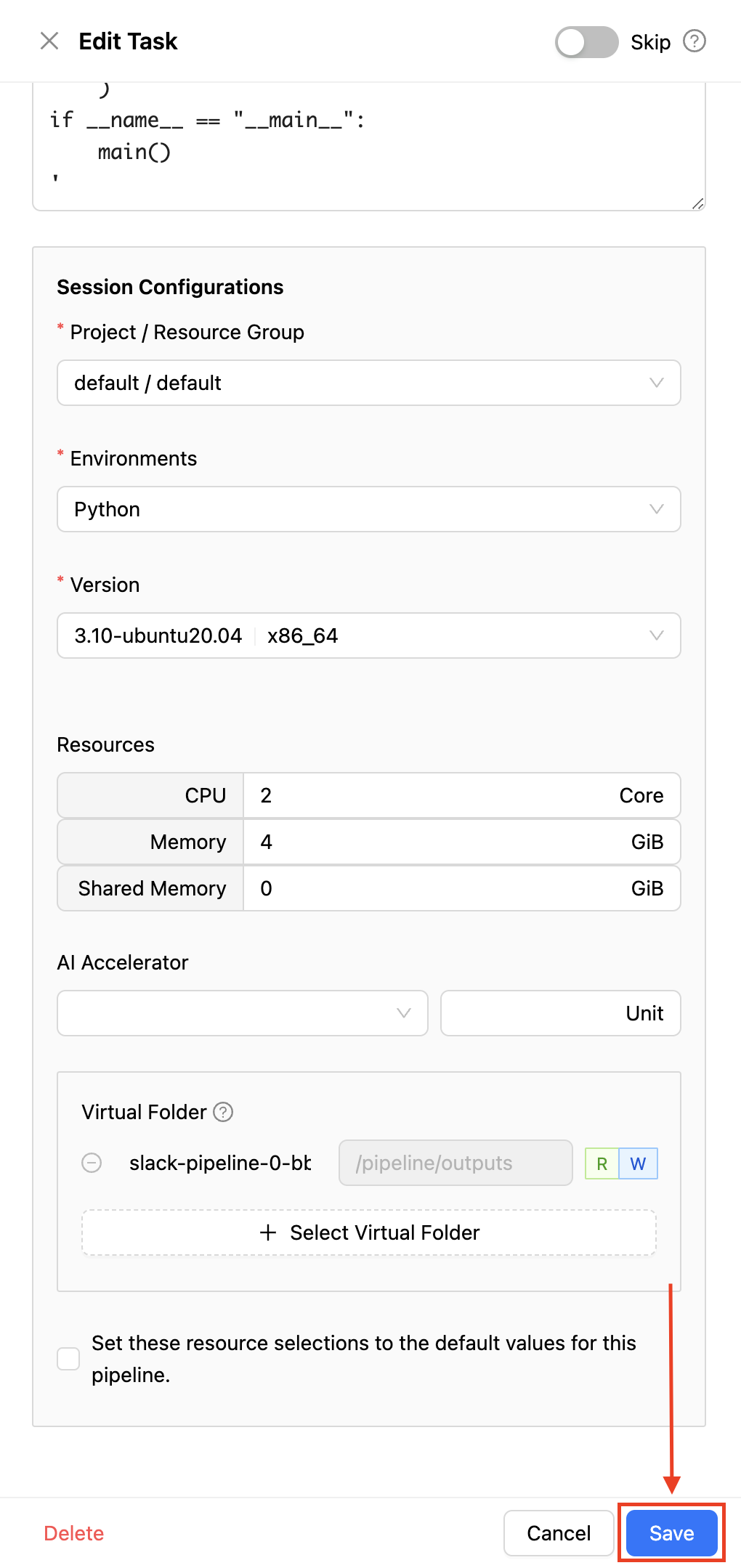
slack-alarm-task 태스크에도 알맞은 자원을 할당해 준 후 하단의 "Save" 버튼을 클릭하여 태스크를 생성합니다.
태스크 의존성 추가하기
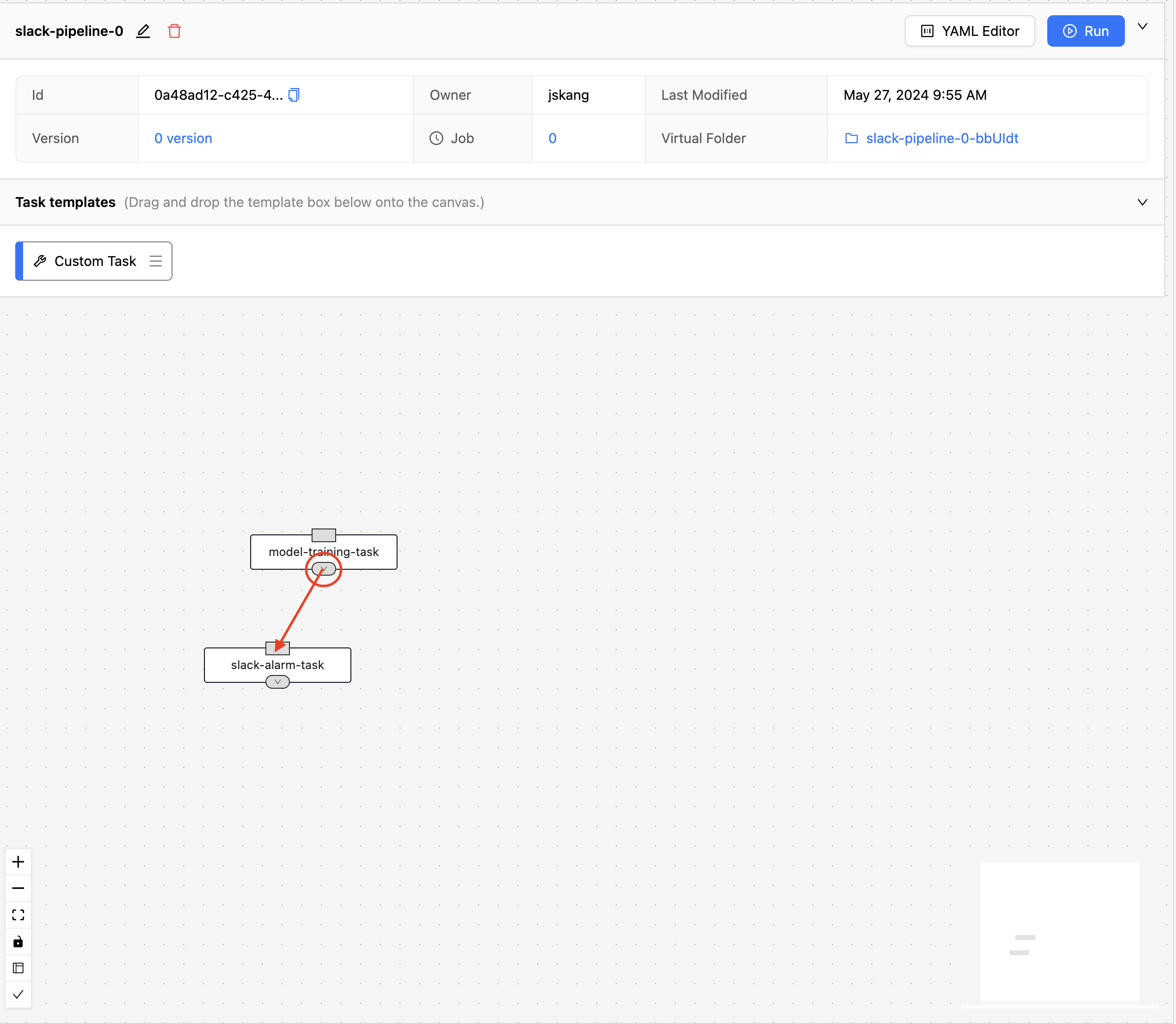
이제 작업 공간에는 두 개의 태스크(model-training-task와 slack-alarm-task)가 존재합니다. 이때 slack-alarm-task는 model-training-task이 종료된 후 실행되어야 하므로 두 태스크 간 의존성을 추가해야 합니다. 먼저 실행되어야 할 태스크(model-training-task)의 하단에서 나중에 실행되어야 할 태스크(slack-alarm-task)의 상단까지 마우스를 끌어다 놓습니다.
파이프라인 실행하기
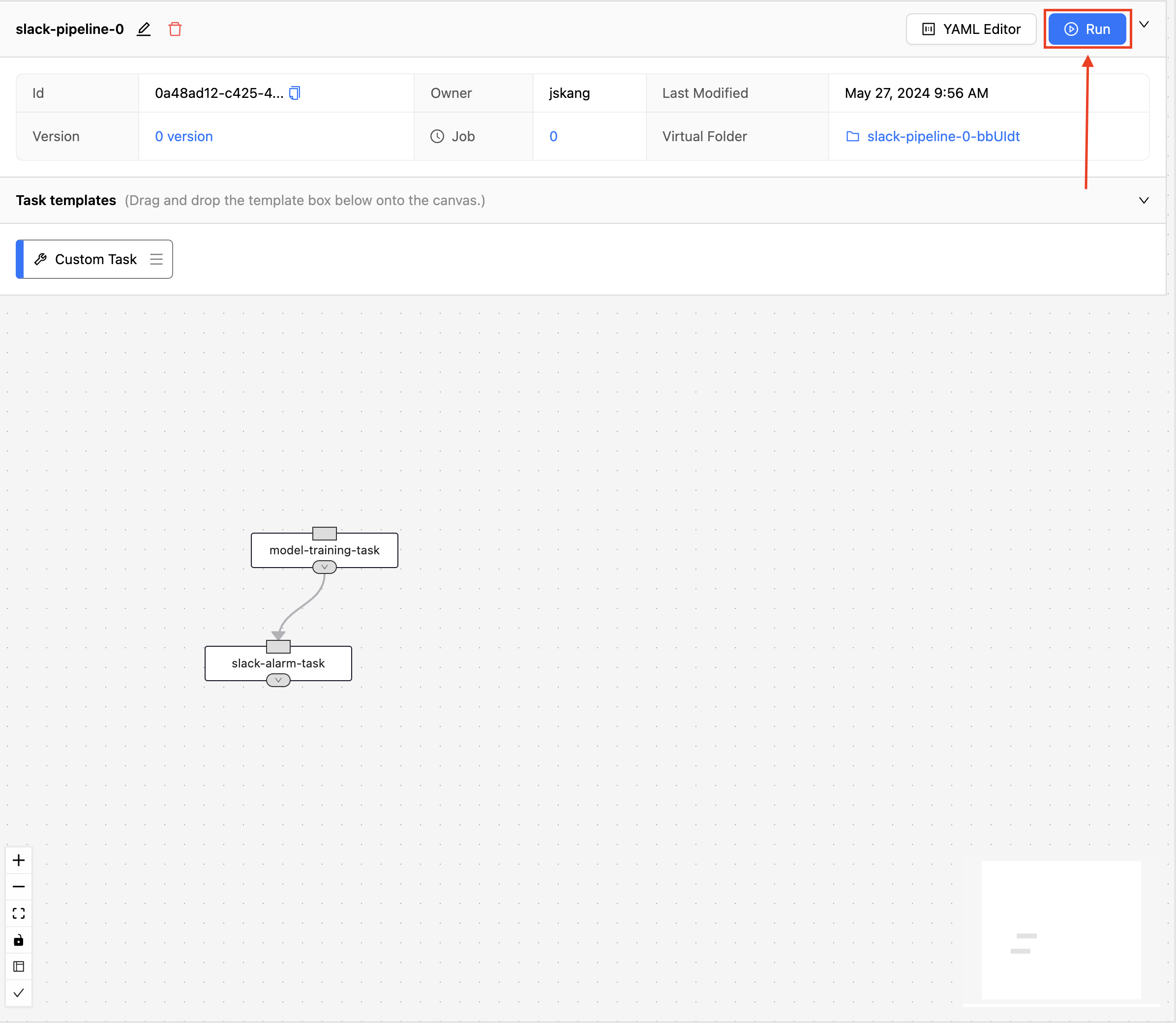
의존성이 추가되어 model-training-task에서 slack-alarm-task 방향으로 뻗는 화살표가 연결된 것을 볼 수 있습니다. 이제 파이프라인을 실행하기 위하여 우측 상단의 "Run" 버튼을 클릭합니다.
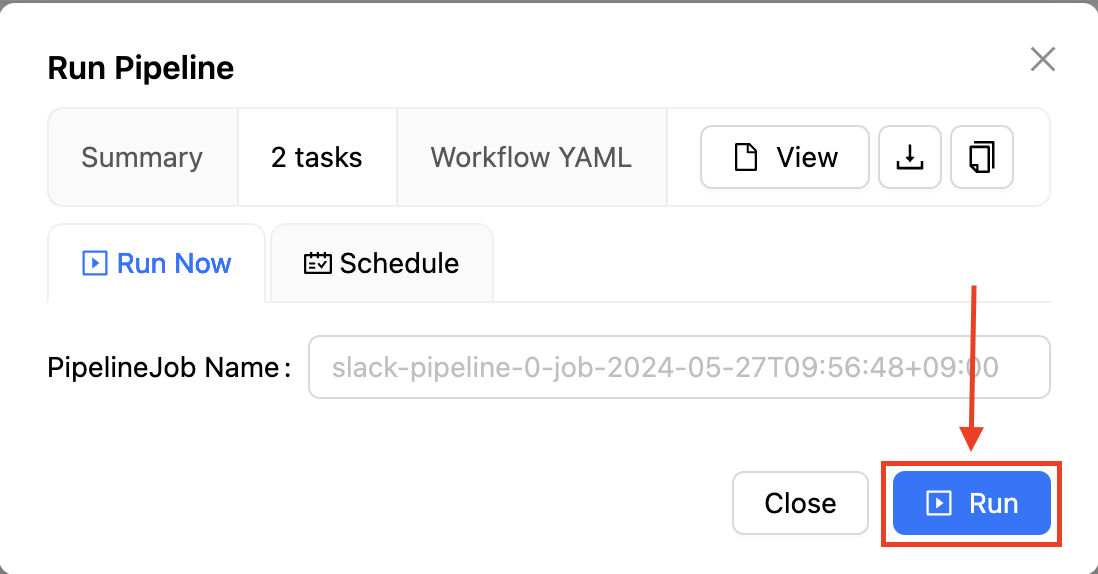
파이프라인을 실행하기에 앞서 파이프라인의 간단한 요약을 검토할 수 있습니다. 2개의 태스크가 존재하는 것을 다시 한번 확인한 후 하단의 "Run" 버튼을 클릭합니다.
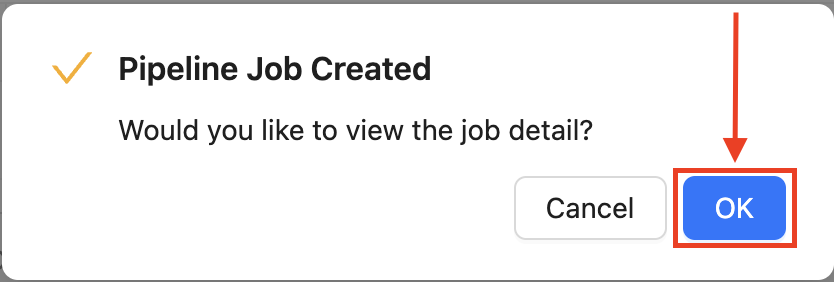
파이프라인이 성공적으로 실행되어 파이프라인 잡이 생성되었습니다. 하단의 "OK"를 클릭하면 파이프라인 잡의 정보를 볼 수 있습니다.
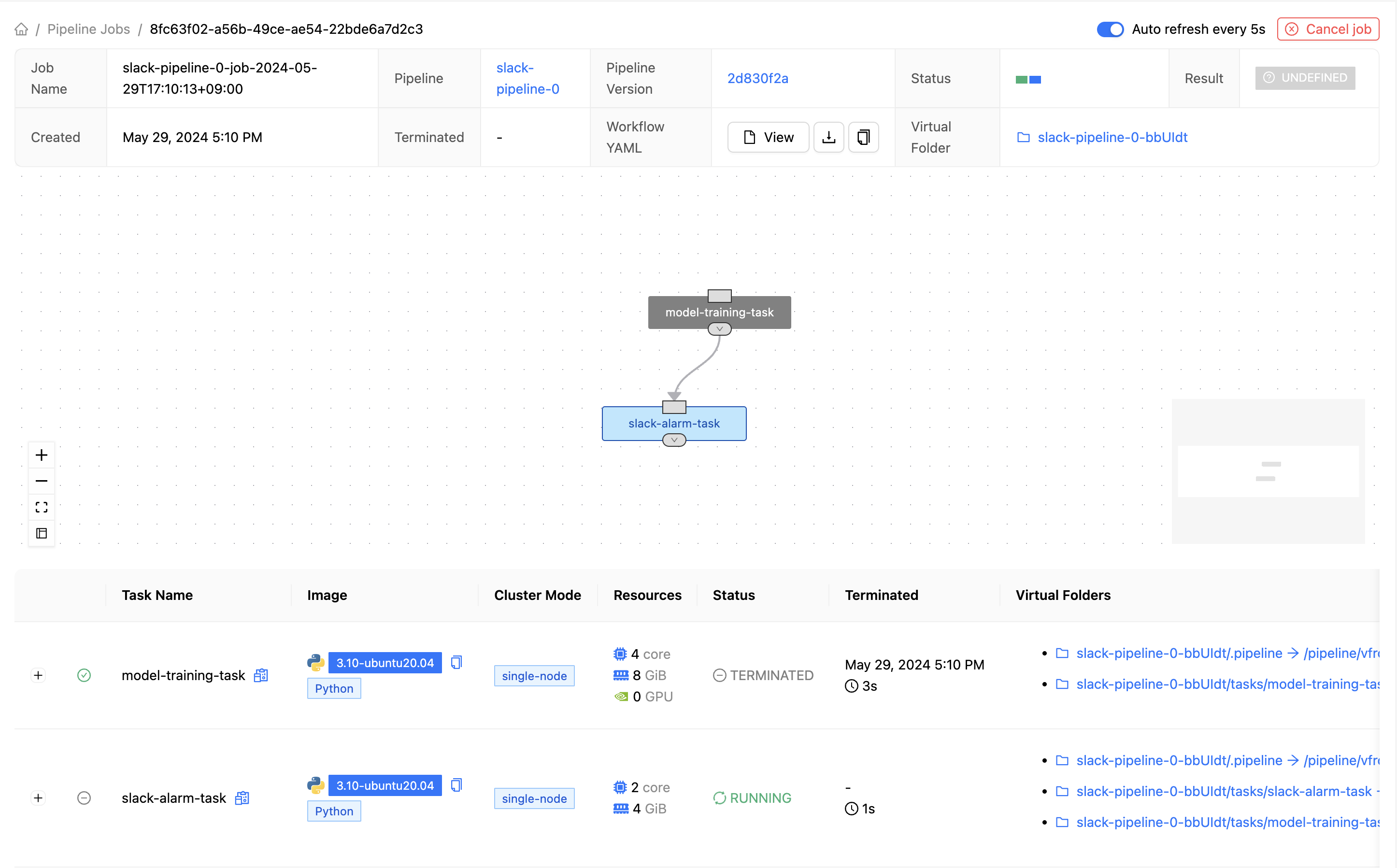
파이프라인 잡이 정상적으로 생성되었습니다. 모델 학습(model-training-task)이 완료된 후 slack-alarm-task가 실행 중인 것을 확인할 수 있습니다.
Slack 알림받기
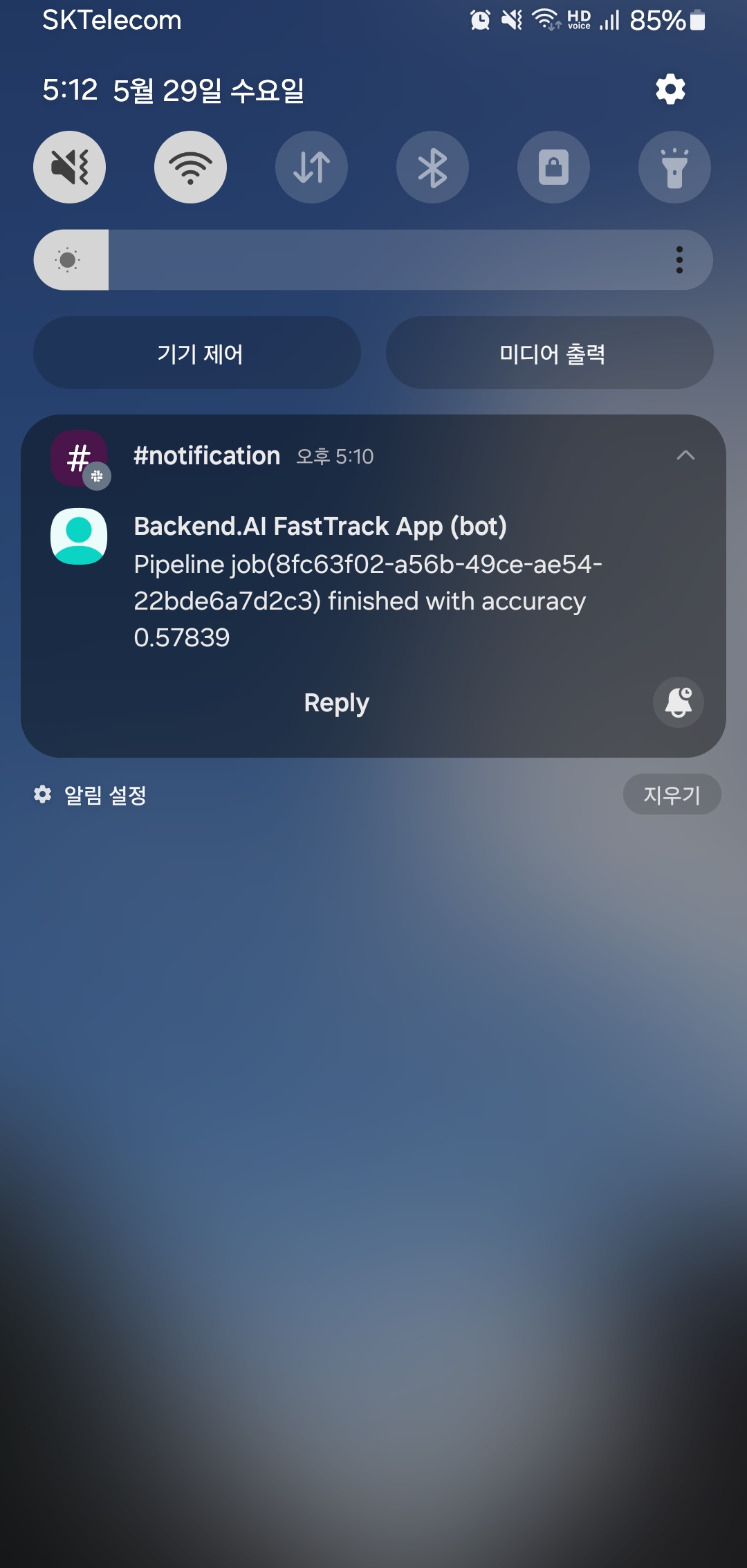
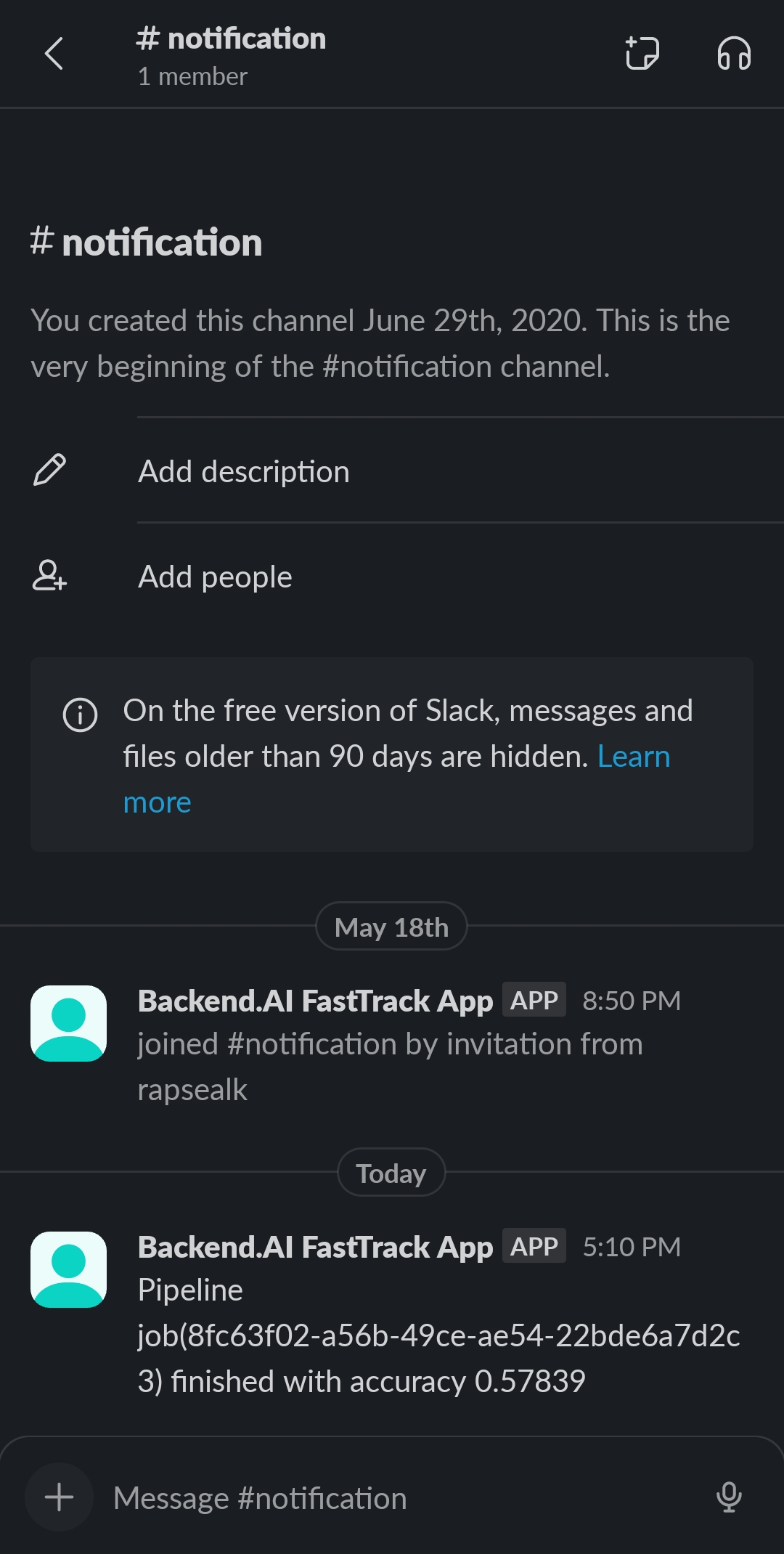
파이프라인 잡 실행 결과가 Slack을 통해 사용자에게 전달된 것을 확인할 수 있습니다. 이제 우리는 편한 마음으로 잠들 수 있게 되었습니다.