
바야흐로 LLM(Large Language Model, 대형 언어 모델)의 시대입니다. 2022년 11월, OpenAI가 발표한 ChatGPT는 AlphaGo의 자리를 이어받아 현대 인공지능의 대명사가 되었습니다. 많은 기업과 연구소에서는 ChatGPT 기반의 자체적인 언어 모델을 개발하는 데 힘을 쏟고 있으며, Meta AI의 Llama 2와 같이 오픈 소스로 공개되는 사례도 증가하고 있어 개인의 접근성도 높아지고 있습니다.
Backend.AI는 대규모 클러스터 운용과 분산처리에 편리성을 제공하고 있어 이러한 LLM을 개발하기 위한 환경으로써 많은 선택을 받고 있습니다. 실제로 다양한 고객사로부터 관련 피드백과 요청을 받고 있으며, 오늘은 그중에 하나를 해결한 과정을 다뤄보고자 합니다.
2023년 4월 4일, NGC Catalog1(NVIDIA GPU Cloud)에서 제공하는 컨테이너 환경에서 특정 패키지를 실행할 때 에러가 발생한다는 이슈를 전달받았습니다. NGC Catalog는 AI/ML, 메타버스, 그리고 고성능 컴퓨팅 어플리케이션을 개발하기 위해 최적화된 환경이 구성된 컨테이너 목록2으로, NVIDIA에서 직접 운영하고 배포하기 때문에 높은 신뢰도를 얻고 있으며 특히 CUDA 환경에서의 표준으로 여겨지고 있습니다. 따라서 해당 환경에서 문제가 발생한다는 것은 앞으로도 다수의 사용자가 마주하게 될 잠재적 위험을 안고 간다는 의미이기에 높은 우선순위로 이 이슈를 해결하기로 했습니다.
문제 재현
우선 정확한 원인을 파악하기 위하여 문제를 재현하는 과정을 먼저 거쳤습니다. 이번 사례는 Columbia University에서 개발한 ViperGPT3를 실행하던 중 bitsandbytes라는 패키지에서 에러가 발생한 경우였습니다. ViperGPT는 아래와 같이 bitsandbytes에 의존성을 갖고 있습니다.
accelerate==0.18.0
backoff==2.2.1
bitsandbytes==0.38.1
cityscapesscripts==2.2.1
git+https://github.com/openai/CLIP.git
decord==0.6.0
dill==0.3.6
...
단순히 bitsandbytes를 import 하는 것만으로 문제 재현이 가능했습니다.
실행 환경은 nvcr.io/nvidia/pytorch:22.05-py3 이미지를 이용했습니다.
$ pip install bitsandbytes # 0.37.1
$ python
>> import bitsandbytes
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
CUDA exception! Error code: OS call failed or operation not supported on this OS
CUDA exception! Error code: initialization error
CUDA SETUP: CUDA runtime path found: /home/work/data/miniconda3/envs/vipergpt/lib/libcudart.so
/home/work/data/miniconda3/envs/vipergpt/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py:136: UserWarning: WARNING: No GPU detected! Check your CUDA paths. Proceeding to load CPU-only library...
warn(msg)
CUDA SETUP: Detected CUDA version 116
CUDA SETUP: Loading binary /home/work/data/miniconda3/envs/vipergpt/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cpu.so...
/home/work/data/miniconda3/envs/vipergpt/lib/python3.10/site-packages/bitsandbytes/cextension.py:31: UserWarning: The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers and GPU quantization are unavailable.
warn("The installed version of bitsandbytes was compiled without GPU support. "
bitsandbytes는 실행 환경에 설치된 모든 CUDA 디바이스를 순회하며 Compute Capability4를 확인합니다. 이때 아래와 같은 방식으로 libcuda.so를 이용하여 실행 환경에 설치된 CUDA 디바이스의 개수를 확인하도록 되어 있었습니다. 그중 cuDeviceGetCount()5를 호출할 때 에러가 발생하는 것을 확인했습니다. 바로 304 CUDA_ERROR_OPERATING_SYSTEM 에러였습니다.
def get_compute_capabilities(cuda):
"""
1. find libcuda.so library (GPU driver) (/usr/lib)
init_device -> init variables -> call function by reference
2. call extern C function to determine CC
(https://docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__DEVICE__DEPRECATED.html)
3. Check for CUDA errors
https://stackoverflow.com/questions/14038589/what-is-the-canonical-way-to-check-for-errors-using-the-cuda-runtime-api
# bits taken from https://gist.github.com/f0k/63a664160d016a491b2cbea15913d549
"""
nGpus = ct.c_int()
cc_major = ct.c_int()
cc_minor = ct.c_int()
device = ct.c_int()
check_cuda_result(cuda, cuda.cuDeviceGetCount(ct.byref(nGpus)))
ccs = []
for i in range(nGpus.value):
check_cuda_result(cuda, cuda.cuDeviceGet(ct.byref(device), i))
ref_major = ct.byref(cc_major)
ref_minor = ct.byref(cc_minor)
# 2. call extern C function to determine CC
check_cuda_result(cuda, cuda.cuDeviceComputeCapability(ref_major, ref_minor, device))
ccs.append(f"{cc_major.value}.{cc_minor.value}")
return ccs
bitsandbytes란?
Transformer의 등장 이래로 언어 모델은 높은 성능 향상을 보였고, 더 많은 Transformer 블록을 쌓아 모델의 규모를 키우는 것이 트렌드가 되었습니다. 이로 인해 모델을 학습시키는 것뿐만 아니라 서비스할 때마저 수많은 GPU 자원을 요구하게 되었습니다. 예를 들어, 175B의 파라미터를 가지고 있는 GPT-3를 서비스하기 위해서는 약 $15,000의 80GB A100 GPU가 8개 필요합니다. 총 $120,000의 비용이 요구된다는 의미입니다. 이것은 개인뿐만 아니라 기업 혹은 연구소에도 큰 부담이 될 수밖에 없고, 이에 따라 서비스를 위한 추론 모델을 경량화하는 연구가 활발하게 진행되고 있습니다.

bitsandbytes는 University of Washington의 박사과정 Tim Dettmers가 Facebook AI Research(現 Meta AI)와 함께한 연구인 LLM.int8()6를 오픈 소스로 공개한 것입니다. 행렬 곱을 연산할 때 각 벡터를 독립적으로 처리하는 Vector-wise Quantization 방법을 적용하고, 중요한 벡터는 16-bit로 표현하여 손실을 최소화하는 등 8-bit와 16-bit를 혼용하는 기법을 통해 모델의 성능은 유지하면서 크기를 줄이는 성과를 보였습니다. Hugging Face의 Transformer 구현체에도 병합이 되었으며, Llama2, QLoRA, KoAlpaca, 그리고 KULLM 등의 다양한 모델에서 사용되고 있습니다.
원인 파악
문제가 발생하는 지점을 찾아 재현까지 완료하였으니 이제 본격적으로 원인을 파악해야 합니다. 비슷한 사례가 있을지 조사해 봤으나 찾아볼 수 없었습니다. 또한 cuInit()은 정상적으로 호출되었기 때문에 더 원인을 파악하기 어려웠습니다.
import ctypes
count = ctypes.c_int()
libcuda = ctypes.CDLL("libcuda.so")
libcuda.cuInit(0) # 0 (CUDA_SUCCESS)
libcuda.cuDeviceGetCount(ctypes.byref(count)) # 304 (CUDA_ERROR_OPERATING_SYSTEM)
libcudart = ctypes.CDLL("libcudart.so")
libcudart.cudaGetDeviceCount(ctypes.byref(count)) # 304 (CUDA_ERROR_OPERATING_SYSTEM)
조언을 얻기 위하여 아래와 같이 GitHub 레포지토리에 이슈(TimDettmers/bitsandbytes#264)를 등록했고, 패키지를 최신 버전으로 업데이트한 후 다시 시도해 보라는 답을 받을 수 있었습니다. 당시 최신이었던 0.38.0.post1 버전으로 올린 후 다시 테스트했지만 동일한 문제가 발생했습니다. 시간을 너무 지체할 수 없었기 때문에 생각을 전환하여 문제가 되는 부분을 제거하기로 했습니다.

문제 해결
첫 번째 접근은 CUDA-Python7을 사용하는 것이었습니다. CUDA-Python은 NVIDIA에서 공식적으로 배포하는 CUDA Python Low-Level Bindings 패키지입니다. 이전에도 유용하게 사용한 경험이 있어서 바로 떠올릴 수 있었고, 바로 설치 및 테스트를 해보기로 했습니다.
$ pip install cuda-python
from cuda import cuda
from cuda import cudart
cuda.cuInit(0) # (<CUresult.CUDA_SUCCESS: 0>,)
cudart.cudaGetDeviceCount() # (<cudaError_t.cudaSuccess: 0>, 1)
다행히 cudart.cudaGetDeviceCount()가 정상적으로 동작하였고 곧바로 bitsandbytes에 통합하는 테스트를 진행했습니다. 하지만 cuda.cuInit(0)를 호출한 후 torch.cuda.is_available()을 호출하면 에러가 발생했습니다. torch.cuda.is_available() 내부에서 cudaGetDeviceCount()를 호출했기 때문입니다.
from cuda import cuda, cudart
cuda.cuInit(0) # <CUresult.CUDA_SUCCESS: 0>,)
cuda.cudaGetDeviceCount() # (<cudaError_t.cudaSuccess: 0>, 1)
import bitsandbytes
# ...
# /opt/conda/lib/python3.8/site-packages/torch/cuda/__init__.py:82: UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 304: OS call failed or operation not supported on this OS (Triggered internally at /opt/pytorch/pytorch/c10/cuda/CUDAFunctions.cpp:109.)
# return torch._C._cuda_getDeviceCount() > 0
# ...
문제는 다시 원점으로 돌아온 것 같았습니다. 숨을 한번 고르고 위의 에러 로그를 차분하게 다시 읽었습니다. 그러자 무언가 눈에 들어왔습니다.
torch._C._cuda_getDeviceCount() > 0
bitsandbytes는 이미 내부적으로 PyTorch를 사용하고 있었습니다. 즉, PyTorch에 대한 의존성을 가지고 있었습니다. 정확히는 bitsandbytes가 의존성을 갖는 lion-pytorch가 PyTorch에 대한 의존성을 가지고 있었습니다. 그리고 PyTorch에는 이미 CUDA 함수들에 대한 인터페이스가 존재했습니다. 이번에는 이걸 이용해 보기로 했습니다.
다행히 PyTorch에는 bitsandbytes에서 사용하는 CUDA 함수들이 모두 존재했습니다. 기존에 libcuda.so 및 libcudart.so를 통해 호출되던 함수들을 아래와 같이 변경했습니다.
| libcuda/libcudart | torch |
|---|---|
| libcuda.cuDeviceGetCount() | torch.cuda.device_count() |
| libcuda.cuDeviceGet() | torch.cuda.device() |
| libcuda.cuDeviceComputeCapability() | torch.cuda.get_device_capability() |
| libcudart.cudaRuntimeGetVersion() | torch.version.cuda |
변경 후 정상적으로 동작하는 것을 확인한 후, 배포 패키지 버전에 적용하기 위하여 GitHub 레포지토리에 PR을 등록했습니다(TimDettmers/bitsandbytes#375).
후기
PR을 등록한 지 약 두 달이 지난 2023년 7월 14일, 해당 패치가 main 브랜치에 병합되었고 0.40.1 버전에 포함되었습니다.

또한 저자인 Tim Dettmers로부터 피드백을 얻을 수 있었습니다. 이 짧은 글에서 저자의 생각과 철학을 느낄 수 있었습니다.
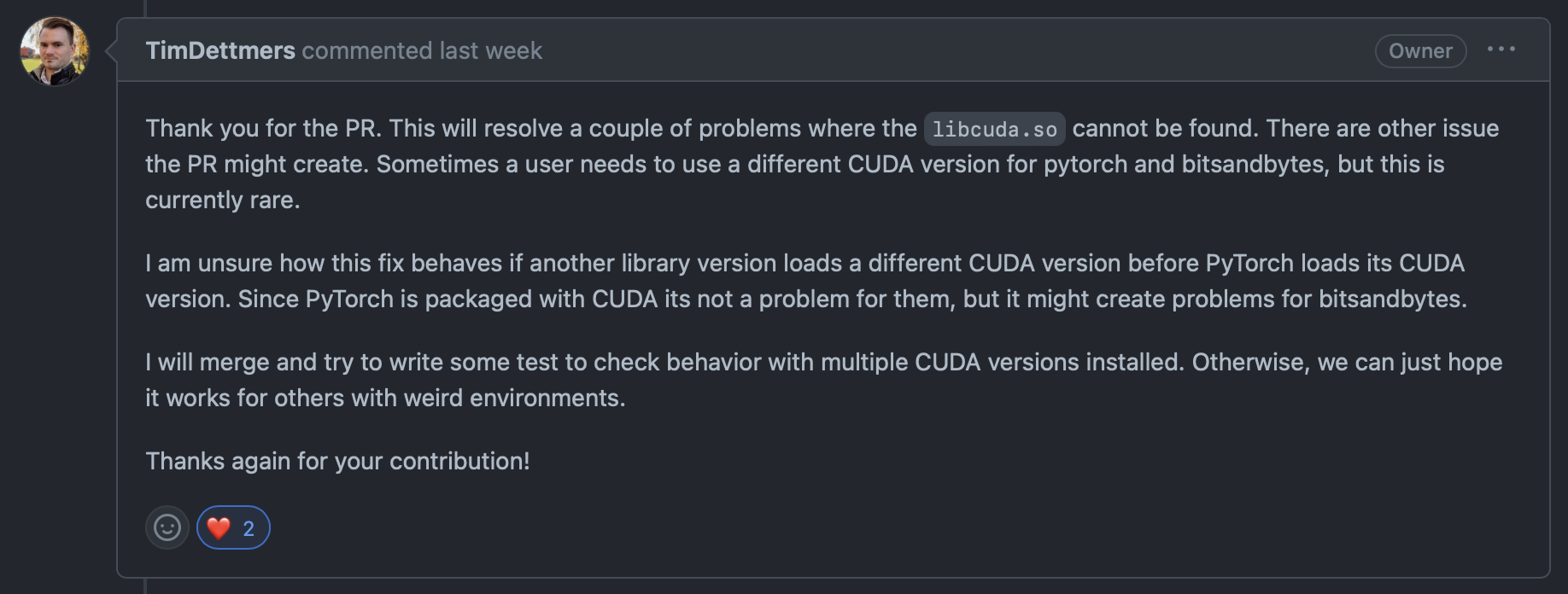
이번 기회를 통해 LLM의 생태계에 대해서 더 자세하게 알아볼 수 있었습니다. 또한 오랜만에 오픈 소스 활동의 재미를 느낄 수 있는 시간이었습니다. 공간적 제약을 뛰어넘어 협업할 수 있다는 점, 그리고 서로의 생각을 나누며 배워갈 수 있다는 점이 오픈 소스 활동의 매력인 것 같습니다. Backend.AI는 엔터프라이즈 버전과 함께 오픈 소스 버전을 운영하고 있습니다. 항상 더 나은 사용자 경험, 그리고 더 나은 개발자 경험을 제공할 수 있도록 노력하겠습니다.
- NVIDIA GPU Cloud↩
- The NGC catalog hosts containers for AI/ML, metaverse, and HPC applications and are performance-optimized, tested, and ready to deploy on GPU-powered on-prem, cloud, and edge systems.↩
- ViperGPT: Visual Inference via Python Execution for Reasoning, March 14, 2023.↩
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capability↩
- https://docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__DEVICE.html#group__CUDA__DEVICE_1g52b5ce05cb8c5fb6831b2c0ff2887c74↩
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale, November 10, 2022.↩
- https://developer.nvidia.com/cuda-python↩