
Backend.AI가 Graphcore의 IPU 지원을 시작합니다. 이번 블로그 글에서는 IPU에 대한 간단한 소개와 함께 Backend.AI에서 IPU를 어떻게 사용할 수 있도록 지원하는지 알아보겠습니다.
Graphcore IPU
현재 딥러닝 가속기는 그래픽 처리 장치(GPU)의 연산 유닛을 프로그래밍하여 활용하는 방식이 대세를 이루고 있습니다. 하지만 점점 성능과 연산량이 높아질수록 전력 소모도 따라서 커지고 있기 때문에 전력대성능비를 높이기 위한 다양한 시도들이 등장하고 있죠. 대표적인 접근 방법으로는 인공지능 전용 프로세서들이 있습니다. 이들은 인공신경망 연산에 보다 특화된 연산 유닛들을 탑재하고 int8/fp8/fp16처럼 일부러 낮은 정확도의 정수·실수 타입을 프로세서 수준에서 직접 다룰 수 있게 하여 전력대성능비를 높이는 것을 목표로 합니다. IPU (Intelligence Processing Unit) 또한 그러한 프로세서의 하나로 Graphcore 사가 개발 중인 AI 및 ML 특화 가속 연산 장치입니다.
구조
IPU는 크게 "타일(tile)", IPU-Exchange™️ 인터페이스, IPU-Link™️ 인터페이스, 그리고 PCIe 인터페이스로 구성되어 있습니다.
타일: IPU-Core™️와 SRAM으로 구성된 IPU의 최소 연산 단위입니다. 1개의 IPU에는 여러 개의 타일1 이 존재합니다. Bow-IPU를 기준으로, IPU 내의 총 SRAM 용량은 900MB입니다. 이는 비슷한 연산 성능을 보여주는 다른 GPU에 비하면 작은 용량이지만, IPU의 경우 다른 GPU2의 L1 Cache와 공유 메모리보다 빠르고 CPU3의 L2 캐시와 비슷한 지연 시간을 보여줍니다.
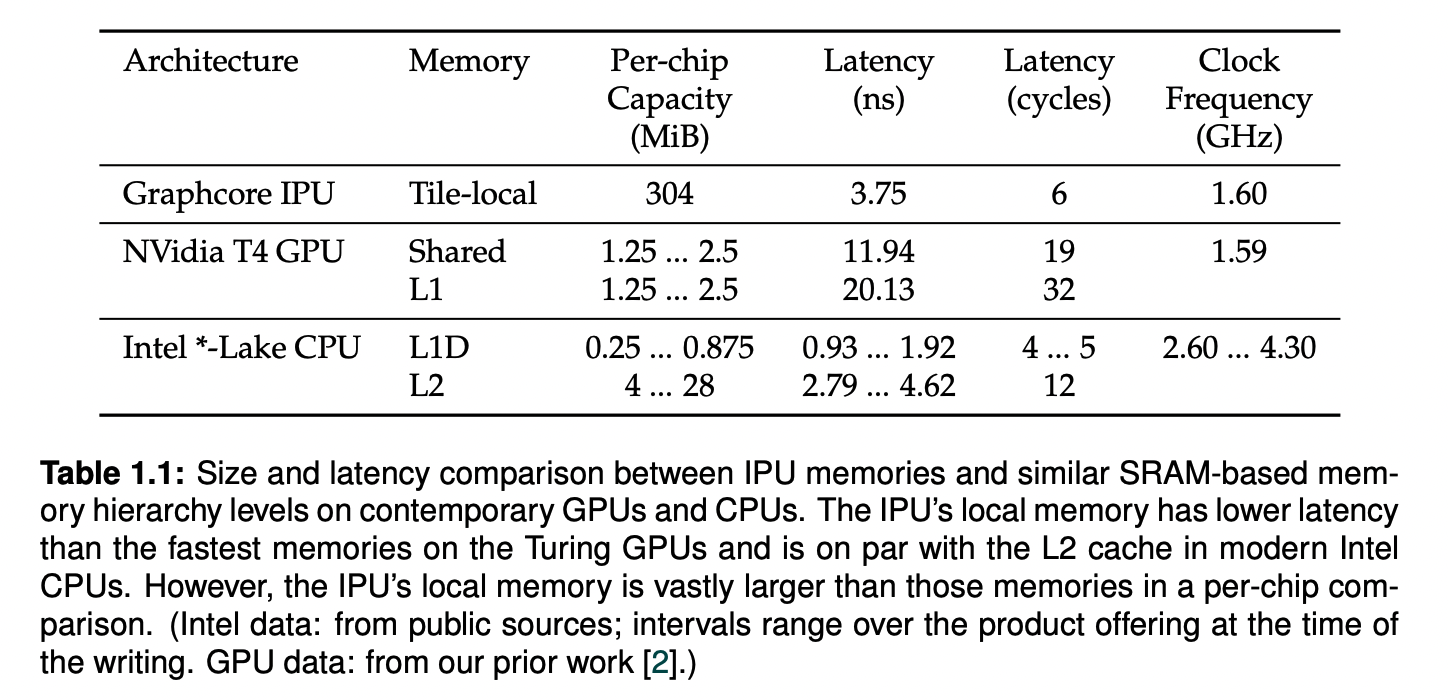
IPU-Exchange™️: 여러 대의 IPU를 동시에 연결하여 사용할 때 프로세서 간 데이터를 전송하는 채널입니다. 최대 11TB/s의, non-blocking 연결을 지원합니다.
IPU-Link™️: 하나의 IPU 내에서의 IPU-Core™️ 간의 데이터를 전달하는 채널입니다. Bow IPU 기준 10개의 IPU-Link™️가 존재하며, 칩 대 칩 간 320GB/s의 대역폭을 지원합니다.
PCI-e: 호스트 컴퓨터와의 연결을 위한 인터페이스입니다. PCI-e Gen4 (x16) 모드를 지원하며, 최대 64GB/s의 쌍방 데이터 전송이 가능합니다.
(참고 페이지: https://www.graphcore.ai/bow-processors) (참고 문헌: Dissecting the Graphcore IPU Architecture via Microbenchmarking - Citadel Security, 2019 (arXiv:1912.03413v1 [cs.DC]))
Bow IPU
Bow IPU는 Wafer on Wafer (WoW) 기술이 적용된 최신 세대의 IPU입니다. 총 1,472개의 연산 코어와 900MB의 메모리를 탑재하였으며, 최대 350teraFLOPS 의 속도로 연산이 가능합니다.
Bow 2000

(Bow 2000 다이어그램 첨부) 4개의 Bow IPU 칩이 탑재된 1U 블레이드입니다. 여러 대의 Bow IPU 간에 데이터 전달을 위한 Infiniband 인터페이스가 존재합니다.
IPU Pod
여러 대의 Bow 2000과 하나의 호스트 시스템으로 이루어진 IPU 클러스터입니다.
- 호스트 시스템 Pod 내에 존재하는 IPU를 통해 연산을 진행하는 서버입니다. Bow 2000과 RoCE (RDMA over Converged Ethernet)로 연결되어 있으므로 연산 시 메모리에서 저지연의 빠른 데이터 전송이 가능합니다.
- Bow 2000 Bow 2000 끼리 연결되어 있는 Infiniband 인터페이스가 존재합니다. 이를 통해, IPU 간 데이터 전송 시에 호스트와 Bow 2000 사이의 데이터 전송의 영향을 받지 않습니다.
- V-IPU
- IPU 칩들끼리 묶어서 Partition 해서 쓸 때 사용
Traditional GPU와의 비교
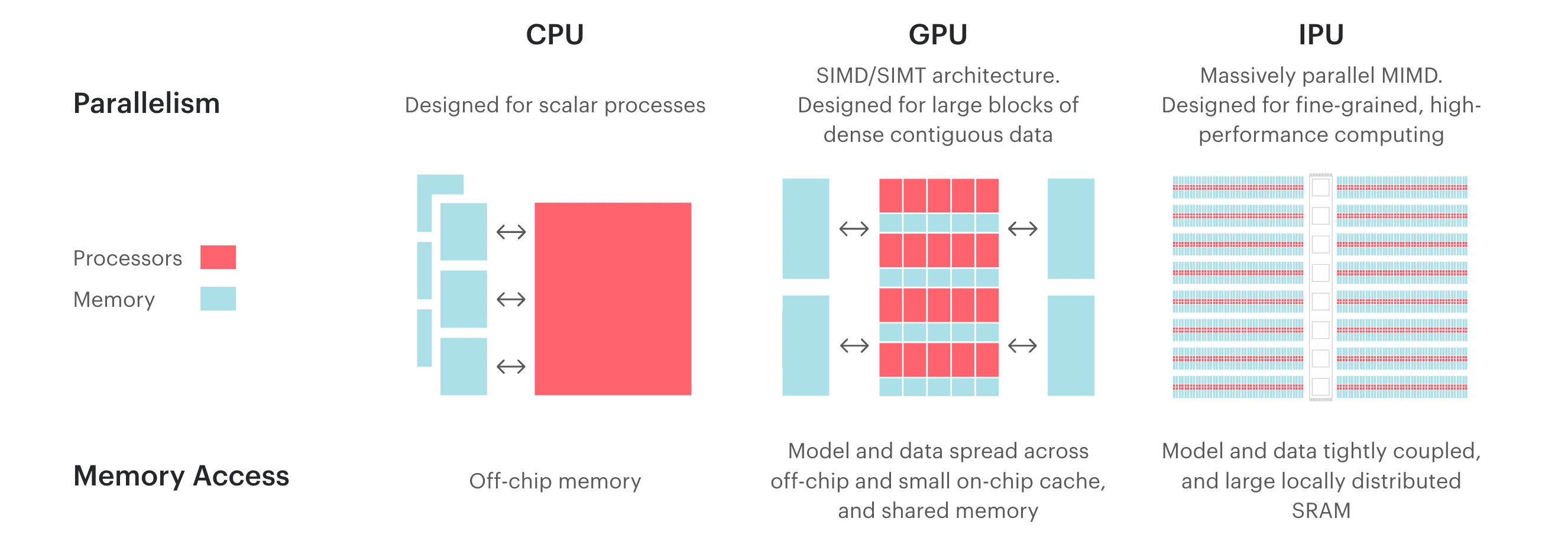
장점
- GPU보다 더욱 세밀화된 연산 유닛1 의 갯수를 통해 더욱 많은 연산을 동시에 처리할 수 있습니다.
- IPU-Exchange™️의 높은 대역폭, 낮은 지연율을 통해 여러 대의 Bow IPU를 활용한 다중 노드 연산을 빠르게 처리할 수 있습니다.
단점
- 기본 세팅으로는 컨테이너를 통한 다중 사용자 환경에서 사용하기 어렵습니다. NVIDIA의 nvidia-docker와 비슷하게, Graphcore 역시 IPU에 접근 가능한 컨테이너를 실행할 수 있도록 gc-docker라는 CLI 툴을 제공하고 있습니다. 하지만 이 경우 Docker의 Host Network의 사용이 강제되어 보안 측면에서 불리하게 작용될 수 있습니다.
Backend.AI with Graphcore IPU
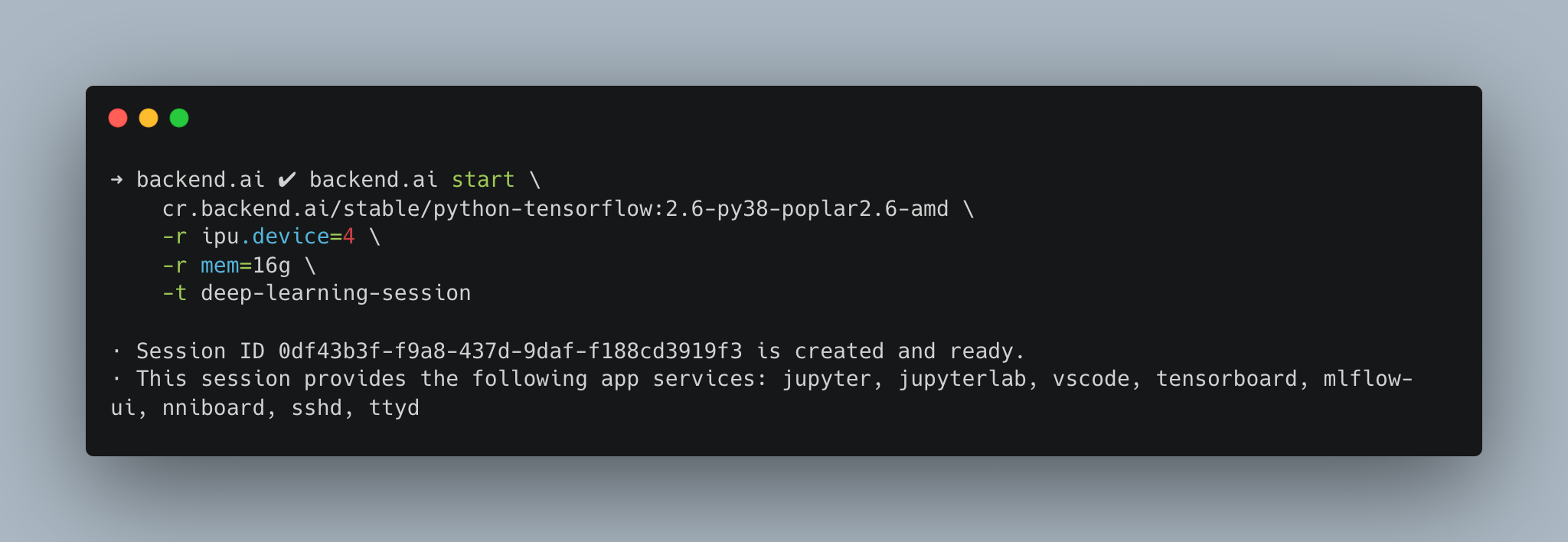
Backend.AI는 클라우드와 엔터프라이즈에서 고도 보안이 요구되는 다중 사용자 환경을 기본 전제로 개발되고 있습니다. 앞서 언급한 것처럼 다중 사용자 환경에서 사용하기 어려웠던 gc-docker의 단점을 Graphcore와의 협업과 Backend.AI Container Pilot 엔진 업데이트를 통해 해결할 수 있었습니다. 그 결과, Graphcore IPU도 Backend.AI에서 다중 사용자 환경에서 완전 격리된 방식으로 성능 저하 없이 그대로 사용하실 수 있게 되었습니다.
- 빠르고 편한 자원 할당
몇번의 클릭만으로 컨테이너 별로 격리된 IPU 분할 할당이 가능합니다.
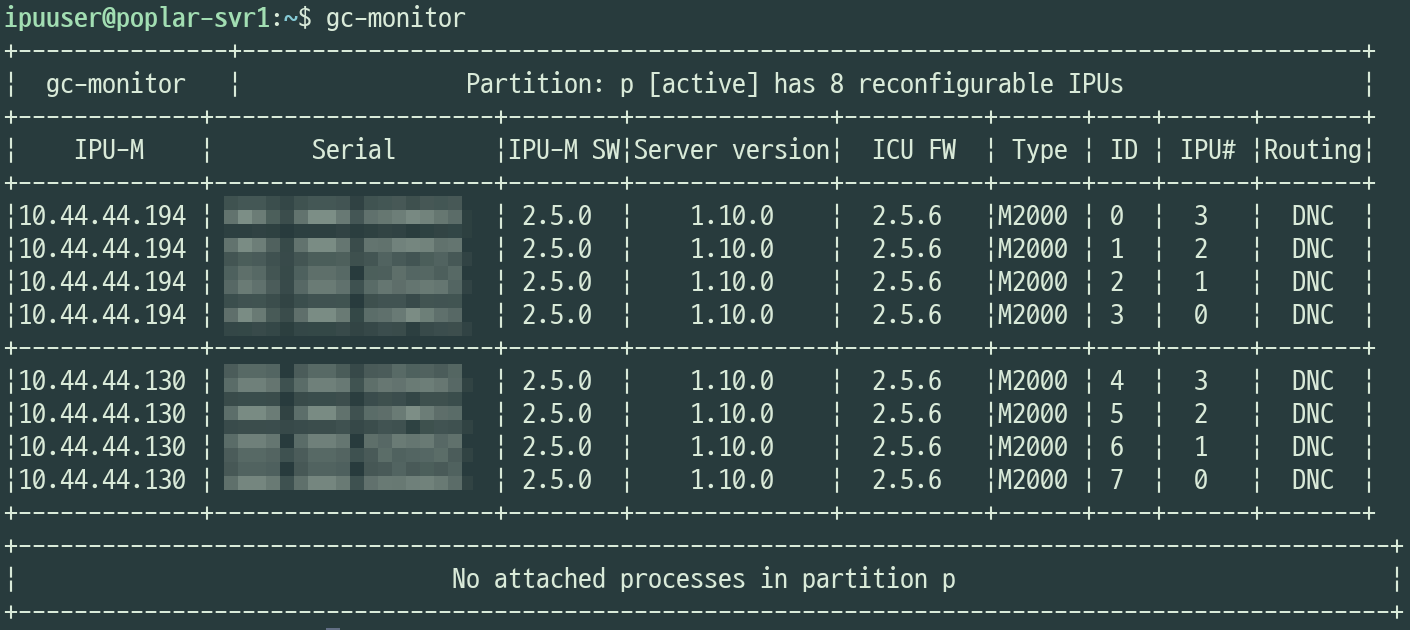
- 격리된 네트워크 환경
Backend.AI를 이용하면 컨테이너를 Host Network에 노출 없이 격리된 세션 사용이 가능합니다. - 여러 개의 IPU Pod을 묶어 사용 가능
Backend.AI에서 여러 개의 분산 컨테이너를 하나의 연산 세션으로 묶어주는 클러스터 세션 기능을 활용하여 여러 대의 IPU Pod로도 분산 학습이 가능합니다.
마치며
Backend.AI는 스토리지 및 AI 가속기 등의 하드웨어의 인식 및 할당을 위한 인터페이스가 효과적으로 추상화되어 있습니다. 이러한 설계는 새로운 하드웨어의 유연한 지원에 큰 도움이 됩니다. 이번 Graphcore IPU의 Backend.AI 지원 역시 마찬가지였습니다. 이번 업데이트로 Graphcore IPU는 CUDA GPU, ROCm, GPU, Google TPU에 이어 4번째로 Backend.AI에서의 사용을 보장하는 AI 가속기가 되었습니다. 앞으로도 Backend.AI는 새로운 흥-미롭고 강력한 하드웨어의 출시 때마다 앞장서서 하드웨어의 가치를 더해 나가기 위해 노력하겠습니다. 앞으로를 기대해 주세요!
1 Bow IPU 기준 1,472개
2 Nvidia Turing T4 기준
3 Intel Skylake/Kaby Lake/Coffee Lake 기준