
현대 어플리케이션을 이야기할 때 고가용성(High Availability, HA)은 빼놓을 수 없는 개념이 되었습니다. 고가용성은 IT 시스템이 다운타임을 제거하거나 최소화하여 거의 100% 상시 액세스 가능하고 신뢰성을 유지하는 능력을 의미합니다1. 래블업이 개발하고 서비스하는 Backend.AI도 고가용성을 유지하기 위하여 다양한 방법을 적용하고 있습니다.

배경
Backend.AI는 매니저와 에이전트, 스토리지 프록시와 웹서버 등 다양한 컴포넌트로 구성됩니다. 각 컴포넌트들은 각각 분산 환경에서 다중 프로세스로 실행되어 안정성을 높이고 있습니다. 특히 매니저 경우 Backend.AI의 세션 실행 스케줄링 및 여러 핵심 기능을 담당하고 있기 때문에 특히 더 높은 신뢰성을 보장해야 합니다. 현재 매니저에는 부하 분산을 통해 고가용성을 보장하는 Active-Active HA 구조가 적용되고 있습니다.
Backend.AI 매니저의 여러 기능 중 하나는 바로 이벤트 처리입니다. Backend.AI는 에이전트와 세션의 생명 주기(Lifecycle)를 추적하고 최적의 스케줄링을 제공하기 위하여 AgentStartedEvent, DoScheduleEvent 등 다양한 이벤트를 발생시킵니다. 예를 들어 한 Backend.AI Agent 프로세스가 실행될 때 AgentStartedEvent를 생성하게 되고, 이 이벤트를 수신한 Backend.AI Manager 프로세스는 특정 동작(schedule())을 수행하게 됩니다. 또한 Backend.AI Manager는 내부적으로 DoScheduleEvent를 발생시키며 주기적인 스케줄링을 보장합니다. 이때 문제가 발생합니다. 고가용성을 위하여 여러 개의 Backend.AI Manager 프로세스를 실행할 경우, 각 프로세스가 자체적인 타이머를 갖고 이벤트를 발생시킨다면 불필요한 부하가 가해지는 것과 더불어 전체 시스템의 상태가 보장되지 못할 수 있게 됩니다. Backend.AI 매니저는 동일 시스템 내에서 오직 하나의 매니저 프로세스만 이벤트를 생성하는 것을 보장하기 위하여 GlobalTimer를 구현하였습니다. GlobalTimer는 분산 락(Distributed Lock)을 통해 프로세스 간 상호배제성을 확보하고, 오직 하나의 프로세스에서만 이벤트가 발생하도록 합니다.
@preserve_termination_log
async def generate_tick(self) -> None:
try:
await asyncio.sleep(self.initial_delay)
if self._stopped:
return
while True:
try:
async with self._dist_lock:
if self._stopped:
return
await self._event_producer.produce_event(self._event_factory())
if self._stopped:
return
await asyncio.sleep(self.interval)
except asyncio.TimeoutError: # timeout raised from etcd lock
if self._stopped:
return
log.warn("timeout raised while trying to acquire lock. retrying...")
except asyncio.CancelledError:
pass
현재 Backend.AI는 분산 락에 대한 인터페이스인 AbstractDistributedLock을 제공하고 있으며, 실제 구현체로는 FileLock, etcd concurrency API 기반의 EtcdLock, Redis Lock 기반의 RedisLock을 개발하여 사용하고 있습니다.
etcd는 분산 시스템을 계속 실행하는 데 필요한 중요한 정보를 보관하고 관리하는 데 사용되는 분산 오픈소스 키-값 저장소이며2, 대표적으로 Kubernetes 등에서 사용되고 있습니다.
class AbstractDistributedLock(metaclass=abc.ABCMeta):
def __init__(self, *, lifetime: Optional[float] = None) -> None:
assert lifetime is None or lifetime >= 0.0
self._lifetime = lifetime
@abc.abstractmethod
async def __aenter__(self) -> Any:
raise NotImplementedError
@abc.abstractmethod
async def __aexit__(self, *exc_info) -> Optional[bool]:
raise NotImplementedError
요구사항
GlobalTimer는 분산 환경에서 프로세스 단위로 이벤트 생성을 제어하는 역할을 잘 수행하고 있습니다. 하지만 요구사항은 늘 변화하고 소프트웨어는 그에 발맞춰 변화해야 합니다. 이번에 추가된 요구사항은 요청 횟수 제한(rate limit)을 구현하는 것이었습니다. 현재와 같은 부하 분산 방식으로는 매 요청이 동일한 매니저에서 처리된다고 보장할 수 없는데, 각 매니저의 상태가 공유되지 않기 때문에 아래와 같은 문제가 발생할 수 있습니다.
1. 두 매니저의 카운터를 각각 0으로 설정하고 요청 횟수 제한을 1로 설정합니다.
2. 첫 요청을 1번 매니저가 받습니다.
3. 1번 매니저의 카운터를 1만큼 증가시킵니다. (C1: 0 -> 1)
4. 카운터가 최대 허용 횟수에 도달하여 다음 요청은 거절하게 됩니다.
5. 부하 분산에 의해 두 번째 요청을 2번 매니저가 받습니다.
6. 2번 매니저의 카운터는 아직 0이기 때문에 최대 허용 횟수에 도달하지 않았습니다. (C2: 0)
7. 2번 매니저가 요청을 처리합니다.
8. 요청 횟수 제한이 제대로 동작하지 않았습니다!
따라서 이런 한계점을 개선할 방법을 논의하기 위하여 아래와 같은 이슈가 제안되었습니다.
리더로 표현되는 단일 매니저 프로세스에 전역 상태 관리를 위임하기 위하여 합의 알고리즘(Consensus algorithms)을 조사하게 되었고, Kubernetes의 저장소로 사용되는(https://kubernetes.io/docs/concepts/overview/components/#etcd) etcd 등의 프로젝트에서 사용되며 충분한 검증을 거쳤다고 판단되는 Raft Consensus Algorithm(이하 Raft)을 이용하기로 결정했습니다.
Raft 합의 알고리즘
Raft 알고리즘은 2014년 USENIX에 제출된 "In Search of an Understandable Consensus Algorithm"3에서 제안된 방법입니다. 당대 최고의 알고리즘이던 Paxos45는 복잡한 합의 과정으로 인하여 실제로 이해하고 구현하는 데 어려움이 있었고, 제목에도 드러나듯 이러한 문제점을 개선하기 위하여 만들어졌습니다.
But our most important goal — and most difficult challenge — was understandability.
- In Search of an Understandable Consensus Algorithm
Raft 클러스터는 일반적으로 5개의 노드로 구성되는데, 최대 2대의 노드에 문제가 발생해도 quorum을 만족하여 시스템을 유지할 수 있기 때문입니다.
클러스터를 구성하는 각 노드는 아래의 세 가지 상태(리더, 팔로워, 후보자) 중 하나를 가집니다. 일반적으로 각 클러스터에는 최대 한 개의 리더가 존재할 수 있고, 나머지 노드는 팔로워가 됩니다.
- quorum: 의결(議決)에 필요한 최소한도의 인원수를 의미합니다. (N/2+1)
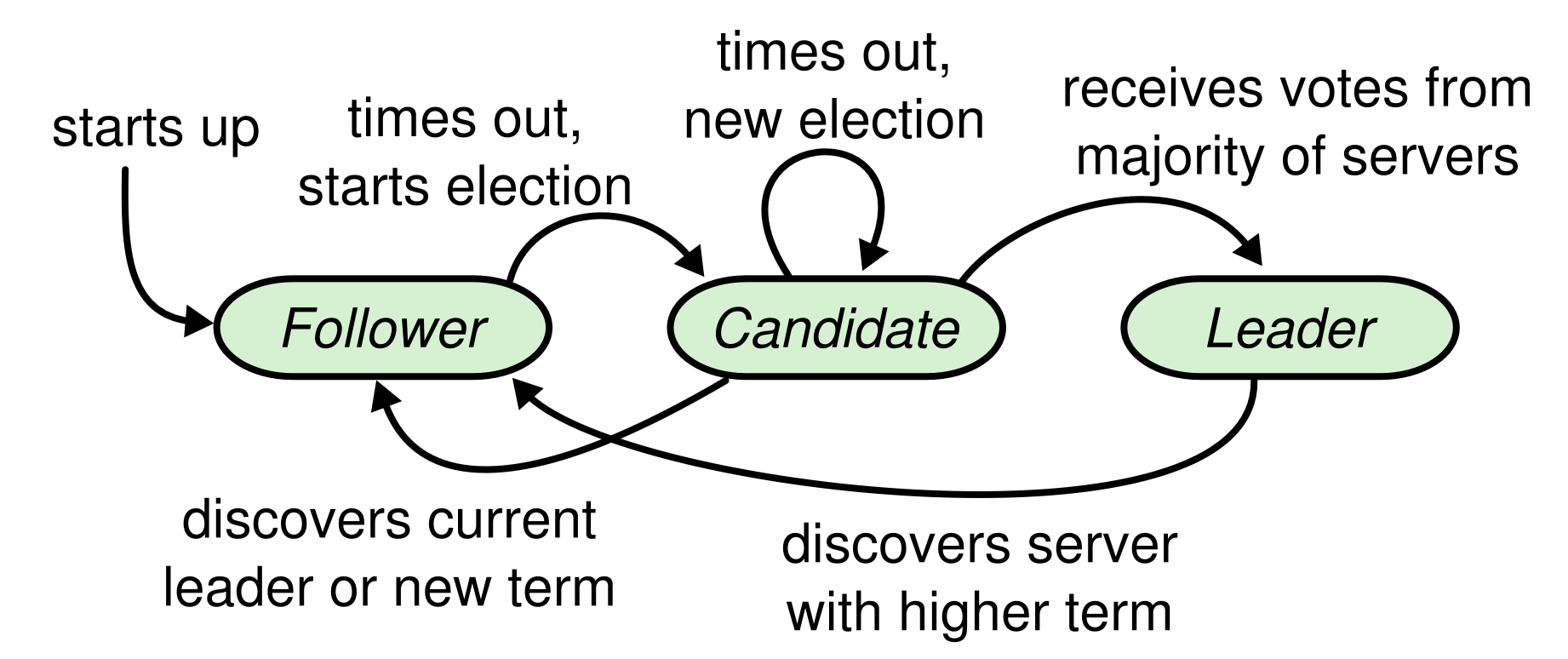
Raft 알고리즘은 선출된 리더에게 모든 권한을 위임하며, 로그의 흐름을 일방향으로 만듦으로써 전체적인 흐름을 이해하기 쉽도록 만듭니다. Raft 알고리즘은 아래와 같은 특징을 가집니다.
- term: 현재 리더 혹은 후보자의 세대를 의미합니다. 리더 선거가 시작될 때마다 1씩 증가합니다.
- index: 로그에서 특정 값의 위치를 의미합니다.
- commit: 로그에 있는 특정 값을 상태 머신에 적용하였음을 나타냅니다.
- commitIndex: 커밋에 성공한 가장 높은 index
- Election Safety: 각 term에는 최대 하나의 리더가 존재합니다.
- Leader Append-Only: 리더는 로그를 덮어쓰거나 삭제하지 않고 새로 추가만 가능합니다.
- Log Matching: 두 로그에 동일한 index와 term을 가진 값이 있다면, 해당 index까지의 모든 값은 동일합니다.
- Leader Completeness: 특정 term에 어떤 값이 로그에 commit되었다면, 이후 세대의 모든 리더는 이 값을 가지는 것을 보장합니다.
- State Machine Safety: 한 서버가 특정 index의 로그 값을 상태 머신에 적용하였다면, 다른 서버는 동일한 index에 있는 다른 값을 적용할 수 없습니다.
위의 특징을 이용하여 Raft는 전체 합의 과정을 서로 독립적인 세 부분으로 나눕니다.
- Leader election: 기존 리더가 동작하지 않으면 새 리더가 선출되어야 합니다.
- Log replication: 리더는 클라이언트로부터 받은 요청 로그를 다른 노드에 복제합니다. 이때 다른 노드들은 리더의 로그를 무조건적으로 수용합니다.
- Safety: 한 서버가 특정 index의 로그 값을 상태 머신에 적용하면 다른 서버는 동일한 index의 다른 값을 적용할 수 없습니다.
이번 글에서는 Raft 노드가 가지는 각 상태에 대하여 알아보고 리더 선출 과정을 코드로 구현해 보도록 하겠습니다.
팔로워(Follower)
팔로워는 자체적으로 요청을 보내지 않고 리더 혹은 후보자의 요청을 받아 대응하는 역할만 수행합니다. 논문에서 제안하는 팔로워의 행동 명세(Behavior Spec)와 이를 기반으로 작성된 코드는 아래와 같습니다.
- 리더와 후보자의 RPC 요청을 처리합니다.
async def on_append_entries(
self,
*,
term: int,
leader_id: RaftId,
prev_log_index: int,
prev_log_term: int,
entries: Iterable[raft_pb2.Log],
leader_commit: int,
) -> Tuple[int, bool]:
await self._reset_timeout()
if term < (current_term := self.current_term):
return (current_term, False)
await self._synchronize_term(term)
return (self.current_term, True)
async def on_request_vote(
self,
*,
term: int,
candidate_id: RaftId,
last_log_index: int,
last_log_term: int,
) -> Tuple[int, bool]:
await self._reset_timeout()
async with self._vote_request_lock:
if term < (current_term := self.current_term):
return (current_term, False)
await self._synchronize_term(term)
async with self._vote_lock:
if self.voted_for in [None, candidate_id]:
self._voted_for = candidate_id
return (self.current_term, True)
return (self.current_term, False)
async def _synchronize_term(self, term: int) -> None:
if term > self.current_term:
self._current_term.set(term)
await self._change_state(RaftState.FOLLOWER)
async with self._vote_lock:
self._voted_for = None
- 일정 시간 동안 리더 혹은 후보자로부터 아무런 요청을 받지 못하면 후보자 상태가 됩니다.
async def _wait_for_election_timeout(self, interval: float = 1.0 / 30) -> None:
while self._elapsed_time < self._election_timeout:
await asyncio.sleep(interval)
self._elapsed_time += interval
await self._change_state(RaftState.CANDIDATE)
리더는 주기적으로 팔로워들에게 하트비트(heartbeat) 메시지를 보냄으로써 자신의 존재를 알려야 합니다. 팔로워는 일정 시간(election_timeout) 동안 아무런 메시지를 받지 못하면 클러스터에 리더가 없는 것으로 판단하고, 자신이 새로운 리더가 되기 위하여 후보자가 되어 선거를 시작합니다.
후보자(Candidate)
후보자의 행동 명세와 구현 코드는 다음과 같습니다.
- 새로운 리더로부터
AppendEntriesRPC 요청을 받으면 팔로워가 됩니다. (팔로워의on_append_etries()참고) - 아래의 절차를 통해 선거를 시작합니다.
- term을 1만큼 증가시킵니다. (term += 1)
- 자신에게 투표합니다.
- 선거 제한시간을 초기화합니다.
- 다른 노드들에
RequestVoteRPC 요청을 보냅니다.
async def _start_election(self) -> None:
self._current_term.increase()
async with self._vote_lock:
self._voted_for = self.id
current_term = self.current_term
terms, grants = zip(
*await asyncio.gather(
*[
asyncio.create_task(
self._client.request_vote(
to=server,
term=current_term,
candidate_id=self.id,
last_log_index=0,
last_log_term=0,
),
)
for server in self._configuration
]
)
)
- 과반수 이상의 노드로부터 득표하면 리더가 됩니다.
for term in terms:
if term > current_term:
await self._synchronize_term(term)
break
else:
if sum(grants) + 1 >= self.quorum:
await self._change_state(RaftState.LEADER)
- 선거 제한시간이 초과되면 새 선거를 시작합니다.
case RaftState.CANDIDATE:
while self.__state is RaftState.CANDIDATE:
await self._start_election()
await self._reset_election_timeout()
await self._initialize_volatile_state()
if self.has_leadership():
await self._initialize_leader_volatile_state()
break
await asyncio.sleep(self.__election_timeout)
리더(Leader)
- 선출 직후 최초의 하트비트(텅 빈
AppendEntries요청) 메시지를 보냅니다. 이후 주기적으로 하트비트 메시지를 보냅니다.
async def _publish_heartbeat(self) -> None:
if not self.has_leadership():
return
terms, successes = zip(
*await asyncio.gather(
*[
asyncio.create_task(
self._client.append_entries(
to=server,
term=self.current_term,
leader_id=self.id,
prev_log_index=0,
prev_log_term=0,
entries=(),
leader_commit=self._commit_index,
),
)
for server in self._configuration
]
)
)
for term in terms:
if term > self.current_term:
await self._synchronize_term(term)
break
- 클라이언트로부터 요청을 받으면 로그에 값을 추가합니다. 해당 값이 상태 머신에 적용된 후 요청에 대한 응답을 보냅니다.
- 팔로워가 리더가 추적하고 있는 값(nextIndex)보다 더 큰 index의 로그 값을 가지고 있을 경우, nextIndex부터 시작하는 로그를 팔로워에게 복제합니다.
- 성공할 경우 리더의 nextIndex와 matchIndex를 갱신합니다.
- 불일치(inconsistency)로 인해 실패할 경우 리더의 nextIndex를 감소시키고 다시 시도합니다.
- 아래와 같은 값(N)이 존재할 경우 commitIndex를 해당 값으로 갱신합니다.
- 과반수 이상의 matchIndex가 N 이상임 (matchIndex >= N)
- N번째 로그의 term이 현재 term과 동일함
리더는 팔로워들에 대하여 각각 nextIndex와 matchIndex를 관리합니다.
- nextIndex: 각 팔로워에게 보내야 할 다음 인덱스
- matchIndex: 각 팔로워에게 성공적으로 복제한 가장 높은 인덱스
마무리
이번 글에서는 Raft 알고리즘에 대하여 간단히 알아본 후 리더 선출을 수행하는 코드를 작성했습니다. 나머지 두 가지 기능(로그 복제, 멤버십 변경)은 실제로 구현하는 과정에서 타이밍 이슈 등 여러 다양한 문제를 마주하게 됩니다. 만약 Raft 알고리즘에 대하여 더 알고 싶다면 저자(Diego Ongaro)의 박사 학위 논문(CONSENSUS: BRIDGING THEORY AND PRACTICE)6를 읽어보는 것을 추천합니다.
마지막으로 ChatGPT는 Raft 알고리즘에 대하여 어떻게 설명해 주는지 확인하며 글을 마치겠습니다.

본 글은 lablup/aioraft-ng의 코드를 참고하여 작성되었습니다. 현재 래블업에서 개발하고 있는 차세대 Raft 프로젝트인 lablup/raftify에도 많은 관심 부탁드립니다.
- https://www.redhat.com/ko/topics/linux/what-is-high-availability↩
- https://etcd.io/↩
- https://web.stanford.edu/~ouster/cgi-bin/papers/raft-atc14↩
- https://lamport.azurewebsites.net/pubs/lamport-paxos.pdf↩
- https://lamport.azurewebsites.net/pubs/paxos-simple.pdf↩
- https://web.stanford.edu/~ouster/cgi-bin/papers/OngaroPhD.pdf↩